
在我们实际的使用 Windows 中,我们在 copy、move 文件会发现有时候,移动的很快有时候慢的跟乌龟一样,如果一个很大的文件夹进行迁移会很慢,但是打包成 zip 然后迁移就相对快多了,或者查看文件属性的时候,会发现有个大小和占用空间,这两者大小还不一样的,接下来这一篇就是讲述为什么。
常见的存储设备分为机械硬盘和固态硬盘。
机械硬盘主要由磁盘盘片、磁头等组成。数据存储在高速旋转的磁性盘片上,磁头通过移动到对应磁道,再等待目标扇区转到磁头下方来完成读写。
固态硬盘是一个个块,通过块里面的储存的电荷量来表示数据。控制器读取这些电荷对应的阈值电压,再判断这个单元代表 0 还是 1,同时值得一提的是,固态是越用越磨损的,用的久了就嗝屁了。
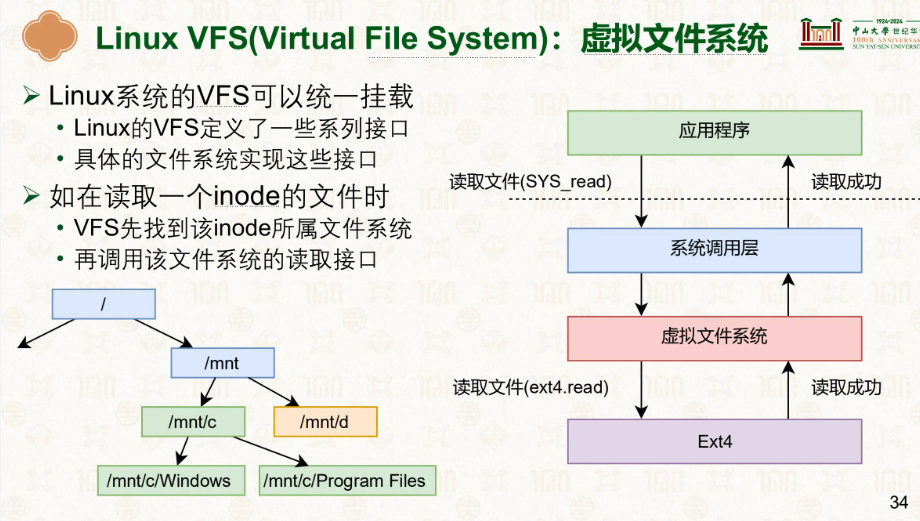
在软件层面,操作系统通过文件系统 (fs),来组织和管理磁盘上的数据。
文件系统负责把磁盘上的块、簇、inode等信息组织起来,并对上层应用提供统一的文件读写接口。
在 Linux 中,inode 是常见的描述文件的形式。
我们想一下文件是怎么存的,假设有一部电影,只需要找个方法把每一块的位置按顺序一一对应起来就行,因为我们不需要进行修改等操作,所以只需要对应不需要考虑文件被修改、删除等应该怎么办。
而另一种情况,假设你在写 PPT,你可以写完下面突然觉得上面有问题去上面改,然后加加加加内容超过了一页怎么办?如果删除了怎么办?
因此,我们需要找一个合适的方式能正确的处理这些情况,一个挺符合直觉的是,既然我们既要存储顺序,也有注意数据大小、位置可能会变动,那存储的是数据的地址即可。
但如果一一对应虽然能找到数据块,但空间太大了…因此就行虚拟地址的多级页表一样,牺牲时间换空间。
直接指针就直接指向 4k 页的地址,间接指针指向索引块(一页),里面全是直接指针,二级间接指针就类似,指向一页全是间接指针的二级索引库。
为什么要这样设计呢?我们想一下,我们写的一般程序的源代码一般也就几kb,如果全采用虚拟地址那样的多级页表,就会很慢。
我们来看看一个 inode 索引的文件最大能多大,12个 4k + 3 个 512 * 4k + 1个 512 * 512 * 4k,也就是 1g + 6mb + 48 kb,所以以这种 inode 形式的单个文件最大是这么大。
inode 本身也会占空间。它保存文件类型、权限、所有者、时间戳、文件大小等信息。不同文件系统里 inode 大小不同,例如 ext4 中常见 inode 大小是 256 字节。
文件元数据描述该文件的大小、类型、权限等。
因此是不是有些明白为什么文件大小和占用空间不匹配?
而文件的文件名和 inode 有关系吗?没关系。
文件名是给人看的,而给操作系统看的是 inode 编号,文件对应着 inode 编号而不是文件名,文件名存储在目录中
那目录是有什么特别的不是 inode 的结构吗?回忆一下,在 inode 的元数据中,有类型,既然有普通文件里类型,那应该也有目录类型。
在目录这个文件中,直接指针指向的也是数据块,块中储存着该目录下的文件编号、文件名等信息。
格式化的本质是按照某种文件系统格式,在存储设备上初始化必要的数据结构,例如超级块、inode 表、位图等。之后操作系统才能按照这种格式来管理文件。
在基于 inode 的文件系统中,超级块存储着该文件系统的元数据,包含文件系统的类型、inode 的个数等。
块、inode 分配信息储存某个块或 inode 是否被分配,第0位置的0、1分别代表第0位置的块或 inode 未分配或已分配。
在 Windows 中,常使用的 FAT: 文件分配表(File Allocation Table),以簇为单位。
在 FAT 中,是通过类似链表的形式,每一个簇通过 FAT 能找到它下一个簇或者直到到头了,原理是,FAT 中该簇对应的位置,如果存在下一个簇,则该位置不为FFFF,会是下一个簇在的索引,所以 FAT 很重要,害怕偶然情况 FAT 受损导致出问题,所以有了 FAT2 备份 FAT1,毕竟同时坏的可能性还是比较低的。
exFAT 是微软为闪存设备设计的文件系统,常用于 U 盘、SD 卡、移动硬盘。相比 FAT32,它支持更大的单个文件和更大的分区;相比 NTFS,它结构更轻量,跨平台兼容性也较好。
现代的 Windows 常用 NTFS (New Technology File System) 格式:
MFT(Master File Table)作为主文件表,在 NTFS 中,每一个文件、目录,甚至文件系统自己的元数据文件,都对应 MFT 中的一条记录。
可类比:
| 文件系统 | 核心结构 |
|---|---|
| FAT | FAT 表 |
| ext2/ext3/ext4 | inode |
| NTFS | MFT 记录 |
NTFS 通常不用这 FAT 那种链表来表示文件,而是用区段,如从 100 开始,连续5个簇(起始簇号 100, 长度 5),$MFT 是描述 MFT 的数据,因为 MFT 也是被当作普通的文件存储在 MFT 上。
当我们直到 inode 编号对应的是文件,而文件名只是给人看的并不重要时,我们就可以做到硬链接,两个不同的文件名的文件,让他们的 inode 编号相同,在操作系统眼里就是相同的文件,这里修改了会同步到另一个文件,或者说不是同步,而是双方就是同一个文件。
删除其中一个硬链接,并不会立即删除文件数据。只有当 inode 的链接计数变成 0,并且没有进程打开它时,文件数据才会被真正释放。
而符号链接就类似 Windows 的快捷方式,文件里面并不是真实的数据,而是它符号链接的文件所在的路径,符号链接是一个独立的文件,有自己的 inode。它的数据内容通常是目标路径。:
在操作系统打开某个文件的时候,会有绑定这个文件的文件描述符(fd),fd 是进程文件描述符表中的一个整数索引。
它指向内核中的打开文件对象。这个对象保存当前读写偏移量、打开模式、状态标志,并进一步关联到 inode/vnode 等文件系统对象,路径主要用于打开文件时查找 inode,文件打开后,fd 并不依赖路径继续工作。
表并不在用户在那里,而是在操作系统维护。
在我们对文件进行操作时,文件的数据是被读取到内存中然后被修改,如果每一次修改如你打一个字、删一行都要实时同步到磁盘,就会导致操作的延迟、速度变得很慢,因此有了定时 flush 等操作,定期将内存中的数据同步到磁盘。
我们定义没有做任何修改的页是干净的,而有了修改的页就是脏页,如果是脏页就要找机会给它写回到磁盘,避免计算器关机导致内存中的数据丢失,使得修改失效。
通过 mmap,我们能将文件映射到内存,这样就方便多了,不需要 read、write 那样,而是把它当作普通的大数组来进行操作。
而我们一般采用延迟映射的方式,当访问到该地址但文件内容并未映射到内存时,会触发缺页异常来将磁盘中文件的内容放到内存里。
而了解完 inode 后,我们就能通过这个来了解另外的省内存的方法,因为储存的都是指针,那我们就能通过类似进程 fork 的共享和写时拷贝(cow)来节省空间。
在实际的使用中,一个操作系统可以挂载多个不同的文件系统,每个文件系统的基于的格式不一定相同,通过虚拟文件系统来通过定义好的抽象接口规范就能正常的使用。









