
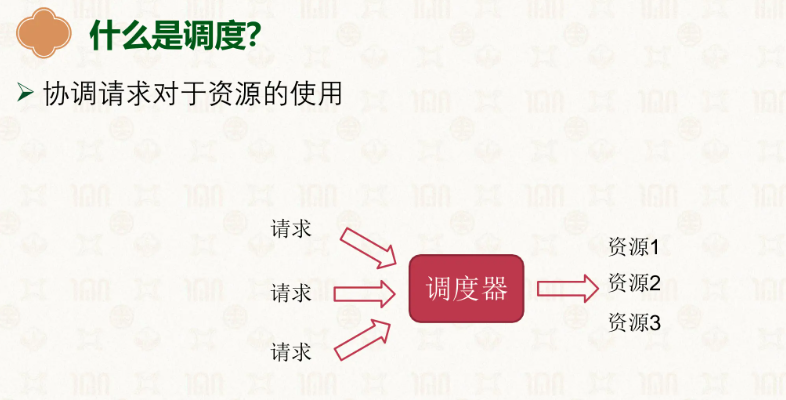
在前面聊了这么多调度,那么让我们了解下调度。
调度也分单核和多核,单核的调度偏向并发,而多核为并行,让我们先了解下单核的调度:

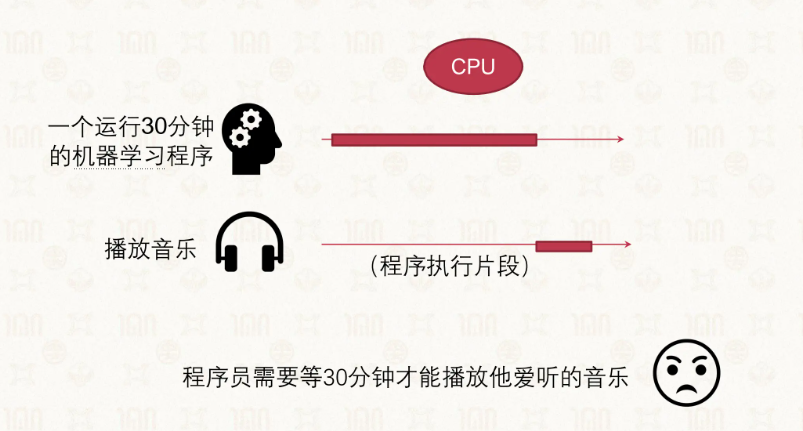
这就是并发的来源,如果一个个任务逐一处理过去,那么…
那么让我们加入调度:
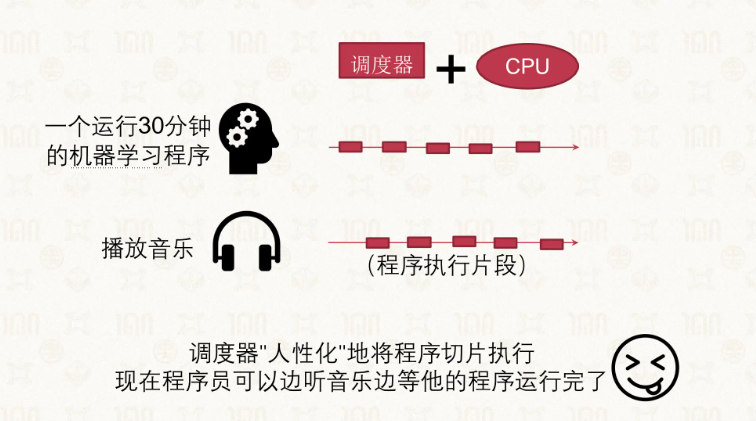

周转时间就是任务到达(提交) 到完成的时间,响应时间就是用户得到任务响应的时间,也就是感知到任务开始进行的时间。
一个个执行没有并发,没有上下文切换的额外开销,但后面的任务必须等前面全部做完,平均周转时间取决于执行顺序;响应时间是最长的,因为任务必须等前面所有任务完成才能开始。

让我们从…
经典调度开始:

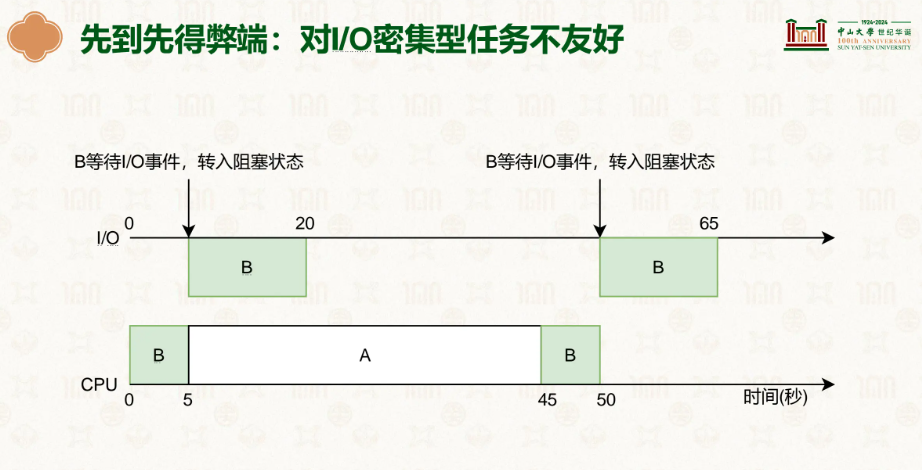
先到先得,最先到达的就做他的,但不考虑工作时间,如果有工作时间很短如一瞬的任务但来得晚,就会等待许久,导致响应时间好长好长…同时对IO密集任务也不友好,B等IO去了然后A过来抢走,B等的IO好了但位置被A抢走了,导致它只能等A的完成,如果好不容易等到了又发生IO,就只能祈祷没人抢位置了。
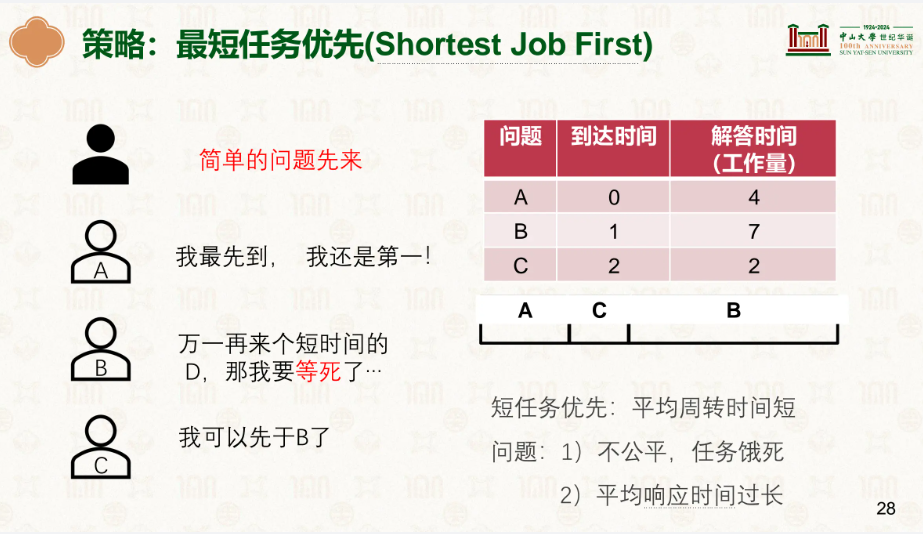
最短任务优先就会导致长任务一直等不到机会,会出现饿死的情况。
这两个都是非抢占式调度,也就是说,在任务执行时不能被主动的打断,除非他自己出现IO等进入堵塞,不然就会一直工作,而抢占式调度就可以主动的暂停当前任务然后切换别的任务来执行。


这个跟最短时间任务优先不同的是,他是看每一个任务当前到结束还有多久,加上正在运行任务A,距离结束还有3s,此时来了任务B,总任务时间是2s,因为是刚来此时距离任务结束还有2s,就会优先执行任务B,就会发生抢占,明显的抢占式调度。
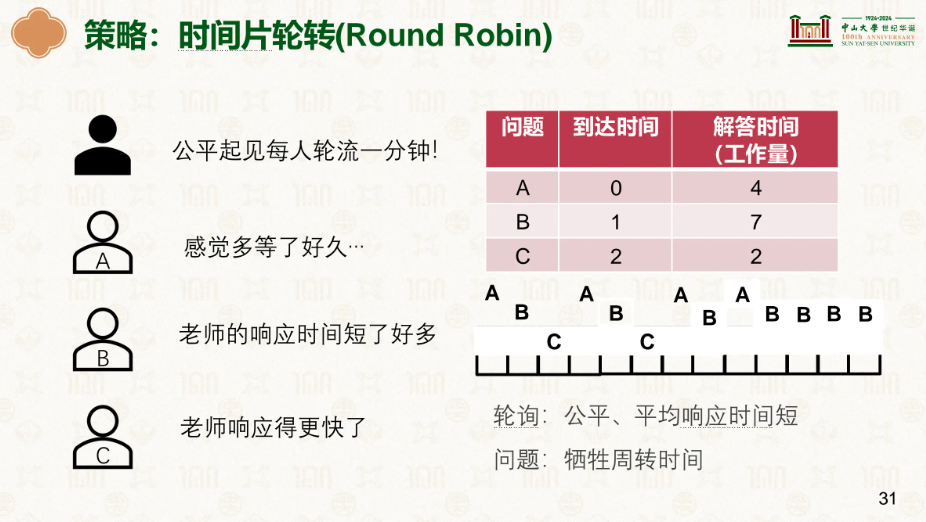
神来咯~,目前最常用的方法,每一个任务给它固定的时间然后切换,时间片轮转,很明显是抢占式调度。
经典调度结束,让我们从优先级的角度看待调度。
优先级调度:
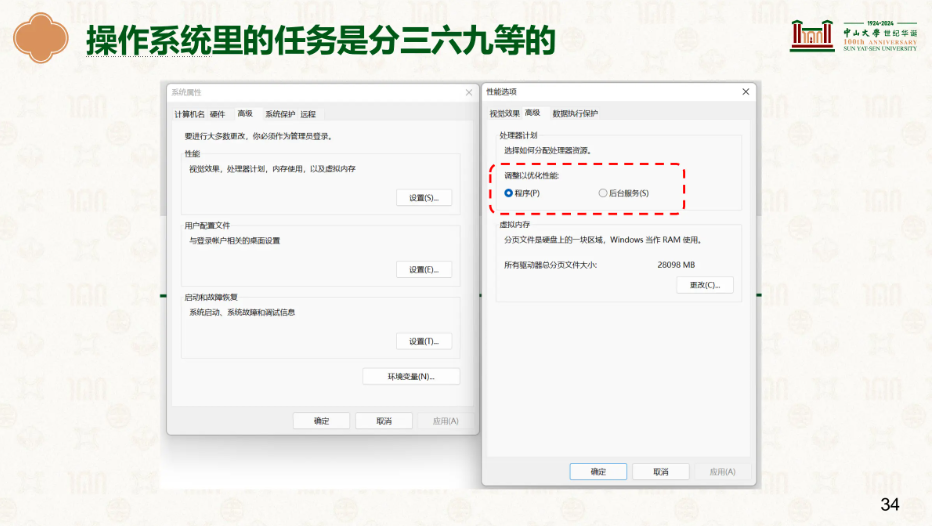
在windows中,你能发现程序优先和系统优先的选项,一般默认是程序优先,也就是如果资源不够时,优先尽量保障程序能正常运行,也就是时间紧,给程序分配更多的时间,后台跑的时间短点,因为程序是用户眼里能看到的,而后台是看不到,程序慢一点用户就会发现变卡了,后台慢一点看的不是很出来。


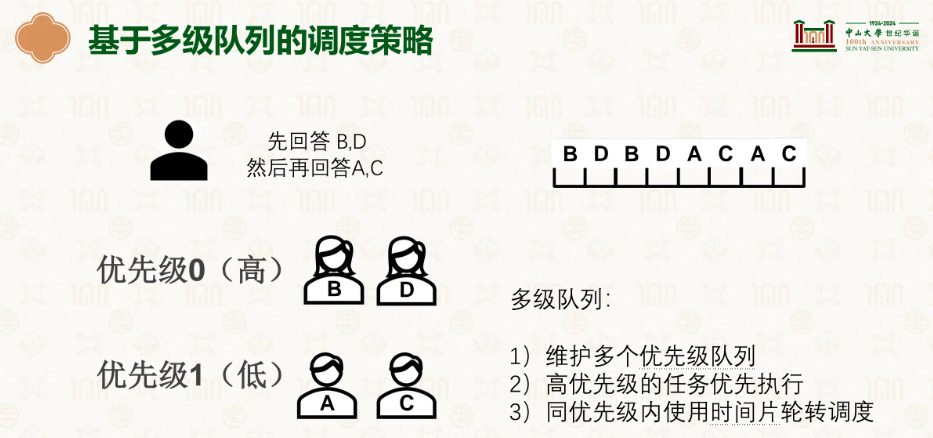
我们基于此,就能通过高优先级的在一块,低优先级的在一块这样,只有当高优先级里的全做完再轮转到低优先级的。
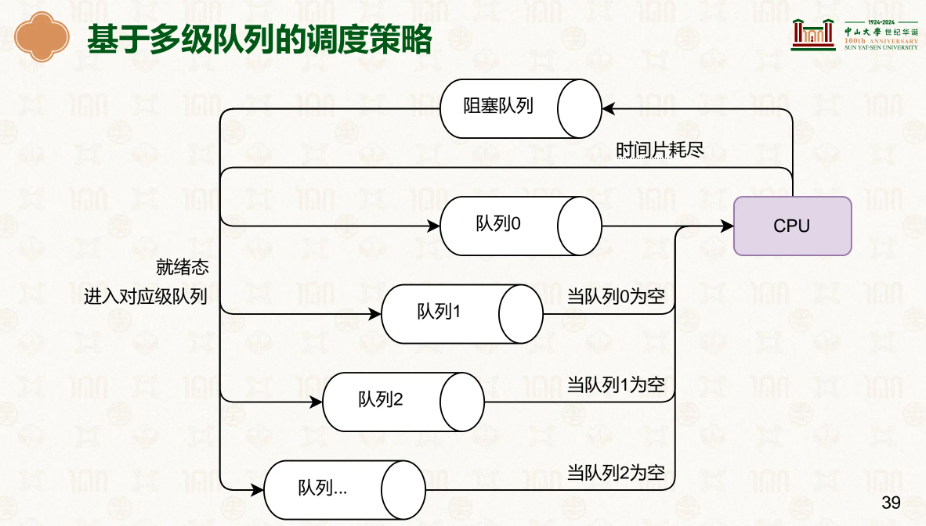
假设每一个任务执行的开始都需要进行一次IO,那按照优先级做下来的速度肯定是慢的,明明能所有任务都走一遍让他们走完IO。
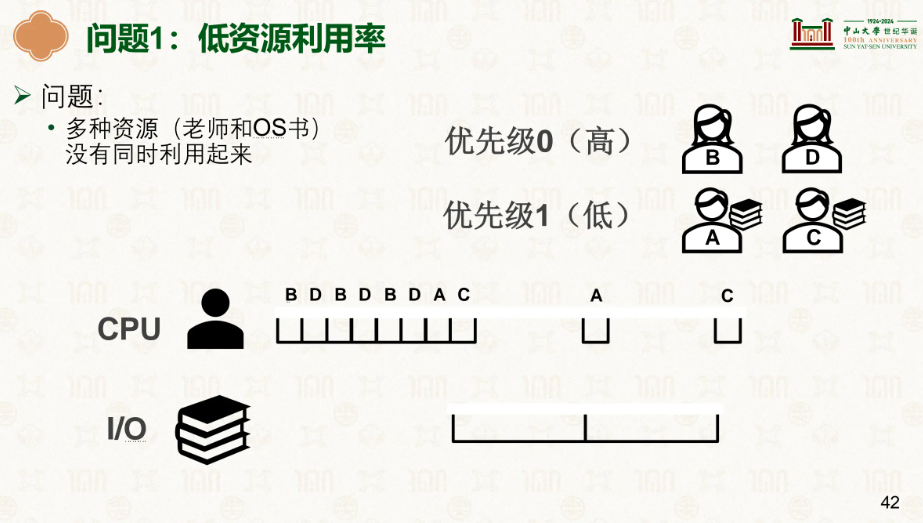

我们思考一个问题,如果任务B拿着一个锁,同时任务B的优先级不高,此时来了任务A,任务A的优先级很高,假设他最高,同时需要这个锁,就会堵塞的等待,若是按正常的执行,任务B会被其他优先级比B高的抢走时间片,但A这个优先级最高的就要等好久。
因此我们引入了优先级暂时的转移,此时A在堵塞的等待B释放锁时,会将自己的优先级给B,此时B就拥有最高的优先级,就会刷刷刷的做完任务,然后释放锁给A,同时优先级也还给了A。
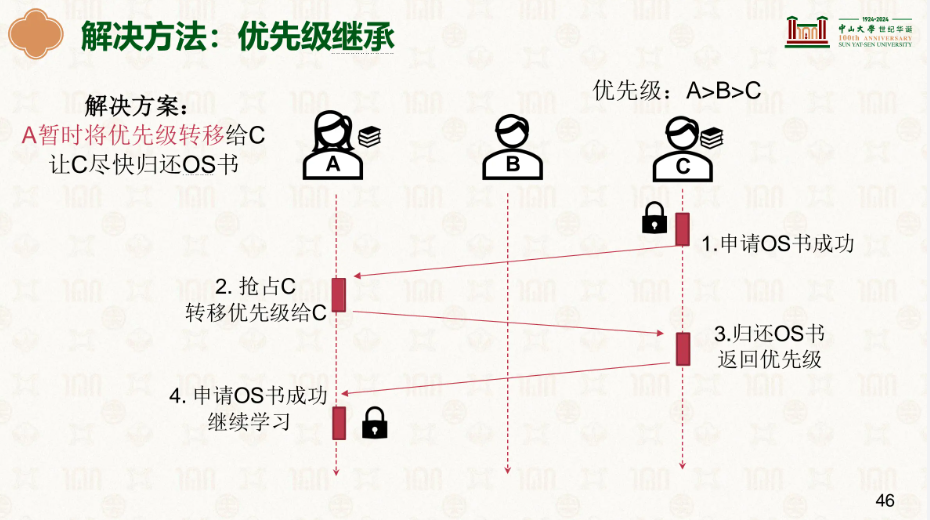
接着就是优先级最可能也是最容易出现的饿死:
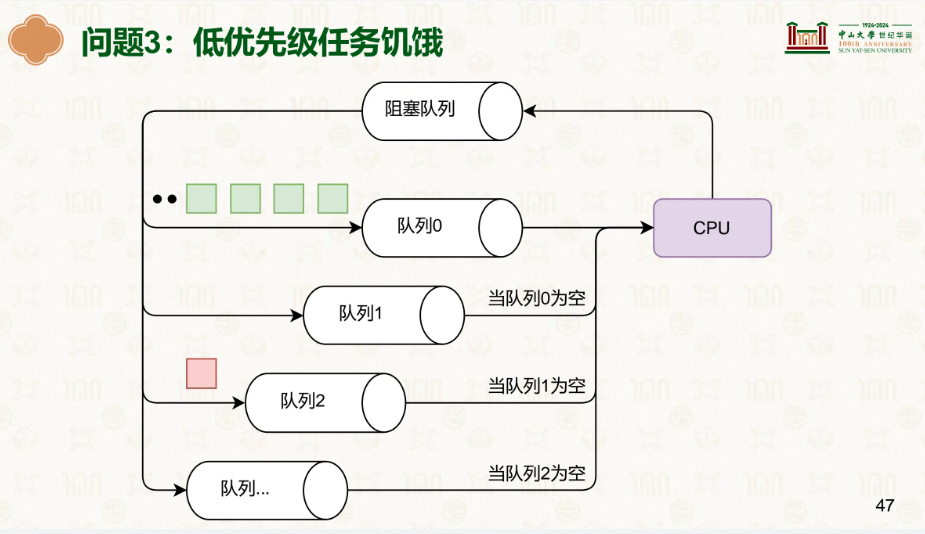
只要比该任务优先级高的任务一直有,低优先级的就无法得到执行的机会,就饿死了,出现了这个:
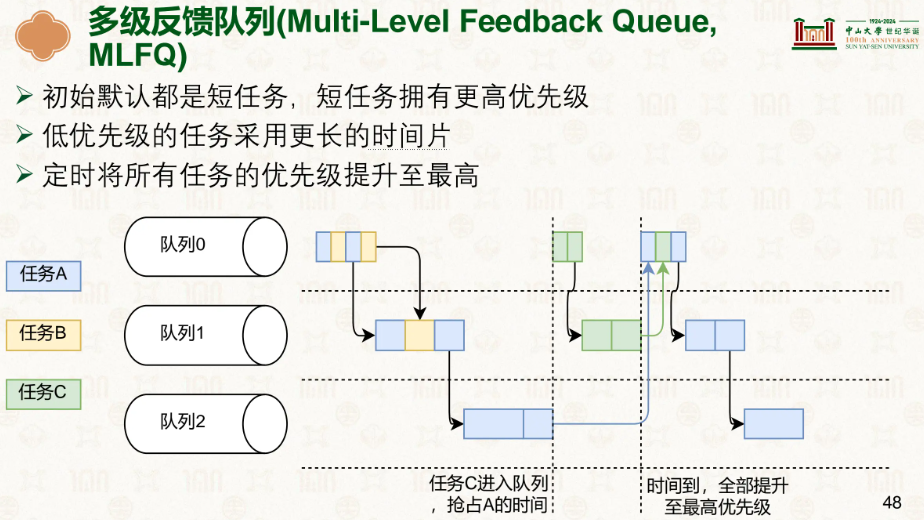
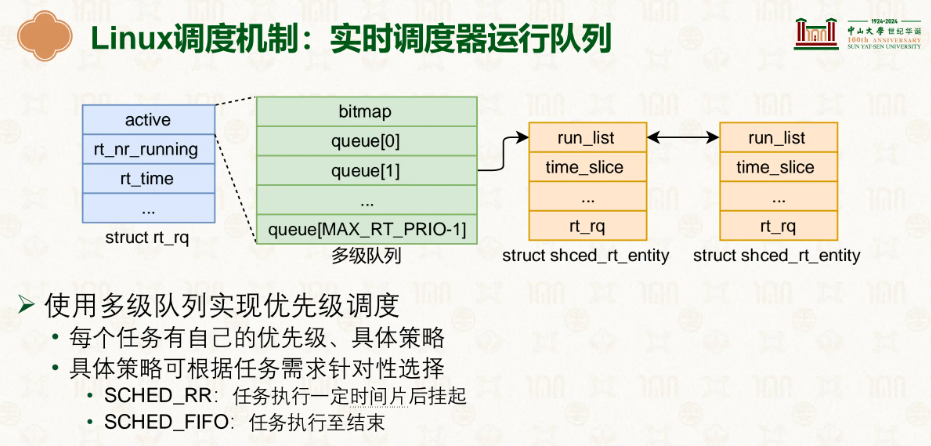
意思很简单,优先级高的,每次都做得时间短,优先级低每次做的时间长,最开始所有任务都是最高优先级,任务用完了当前优先级队列分配的时间片(时间配额)后,被降到更低优先级的队列,每个隔一定时间就将所有任务的优先级全部调回最高,这样所有任务的都有被执行的机会,不会出现饿死的情况。
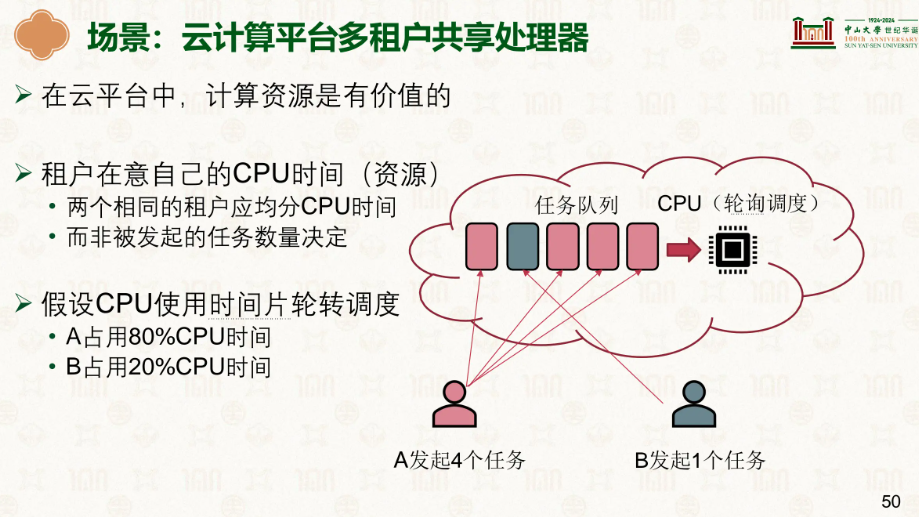
公平共享调度:
这是在云服务器中常用的调度,因为每一个用户花的钱一样,你总不能这个人多一点另一个少一点,这样客户会有意见的~

我们引入ticket,可以认为是手里的票
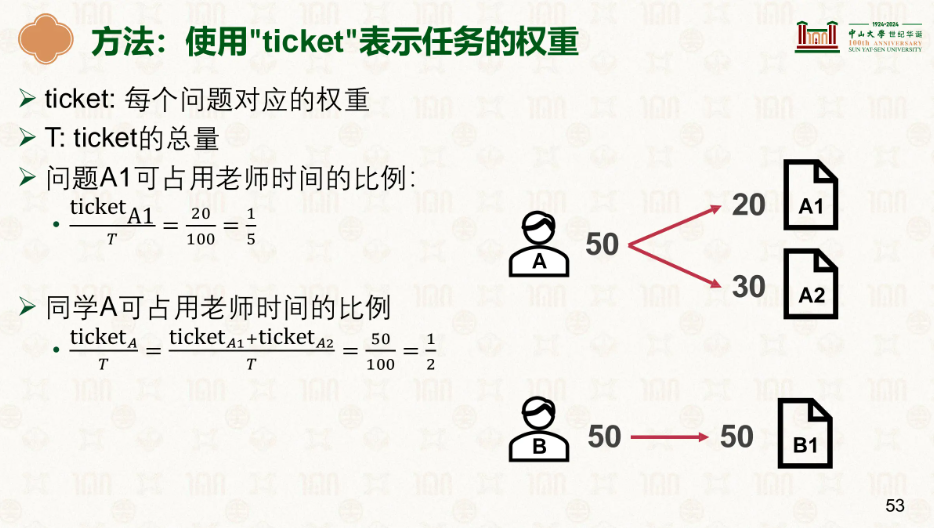
每个人有着自己的票,按照票分到时间,该时间为该用户的时间,其任务的时间不能超过分到的时间。
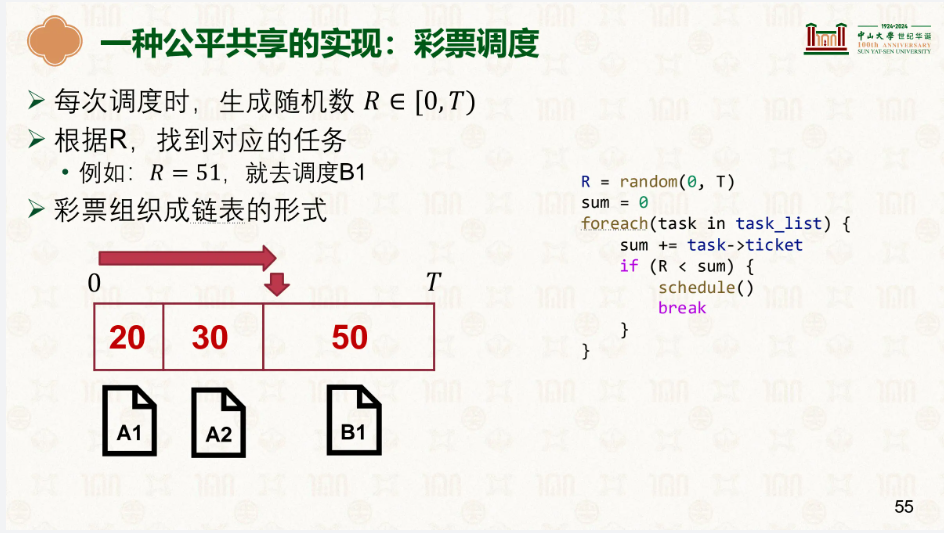
这里彩票调度,就是在列表里每次加上一定的值,然后落到的区间在哪里就调度哪个,ticket越多的就越可能落到该区间,因此就像中彩票一样看看什么情况下会中。
当任务数量很大时,逐个遍历链表效率低,因此我们就加入了调表:

但如果我们手动控制跳多远这也是一种干涉不公平,所以…这里也是通过随机数来决定跳多远。
在某些场景,一个服务器收到了大量用户的请求,而另一个只有几个,此时若按照公平调度的原则,大量请求的服务器很明显很卡顿,但我们又不能违背,此时就多了一种东西,用户手里的票。

用户访问也会有票,它访问什么就会给对应的服务器票来增加它工作的可能性,这样来加快高用户需求的情况(一点也不公平…)。


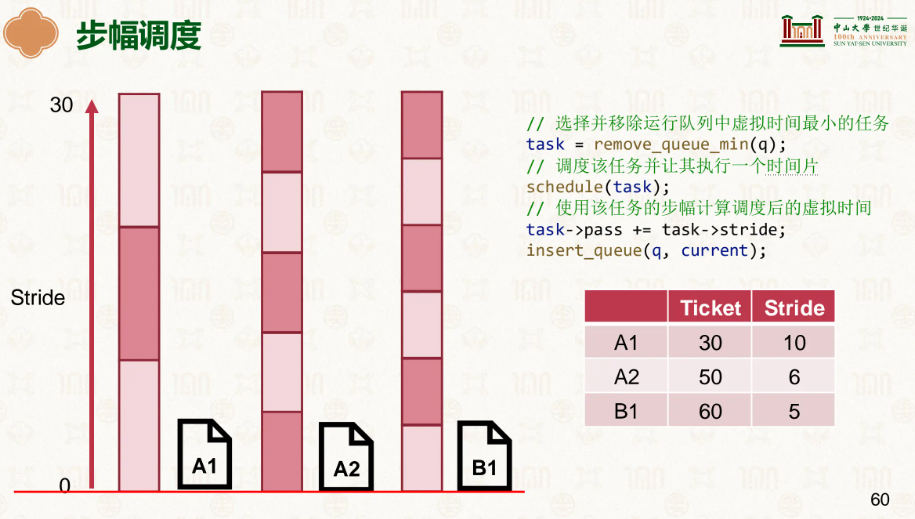
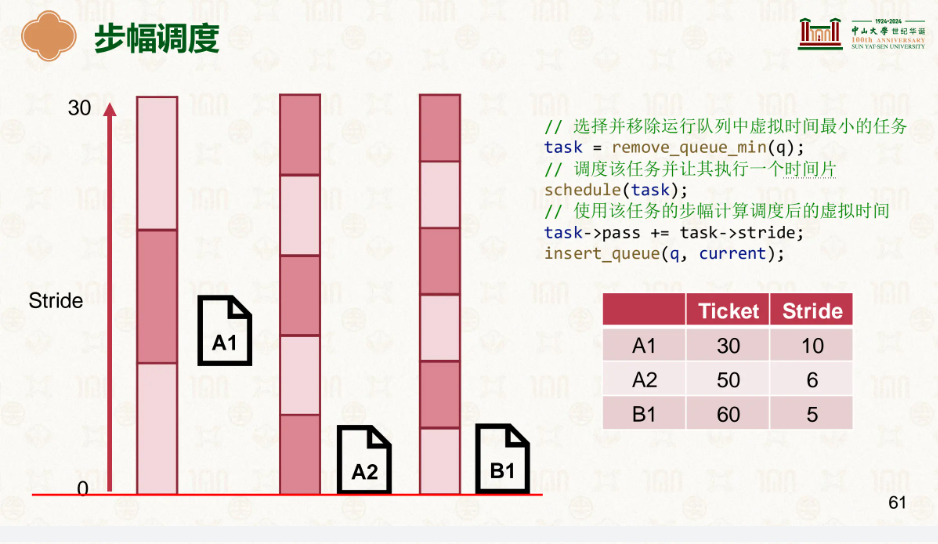
因此我们有了更好的选择,步幅:

票数越多的走的越慢,已达到均衡前进的需求:
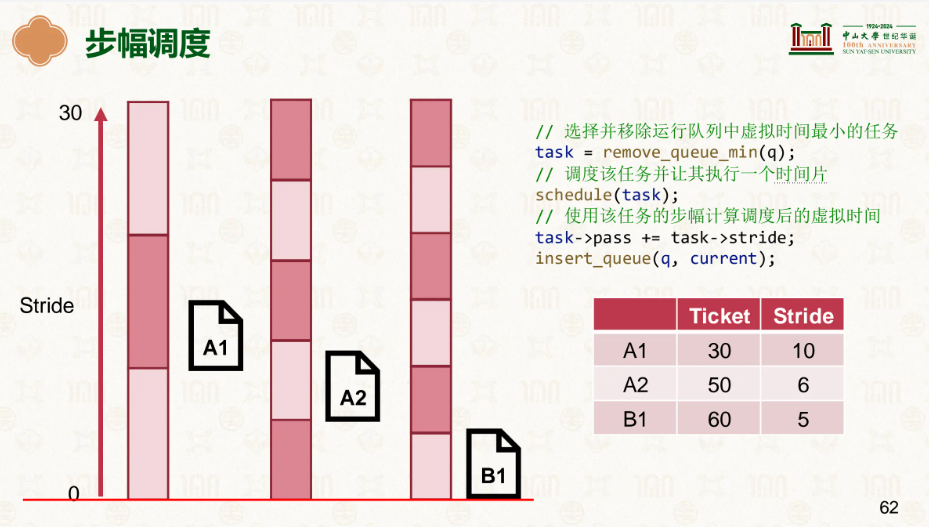
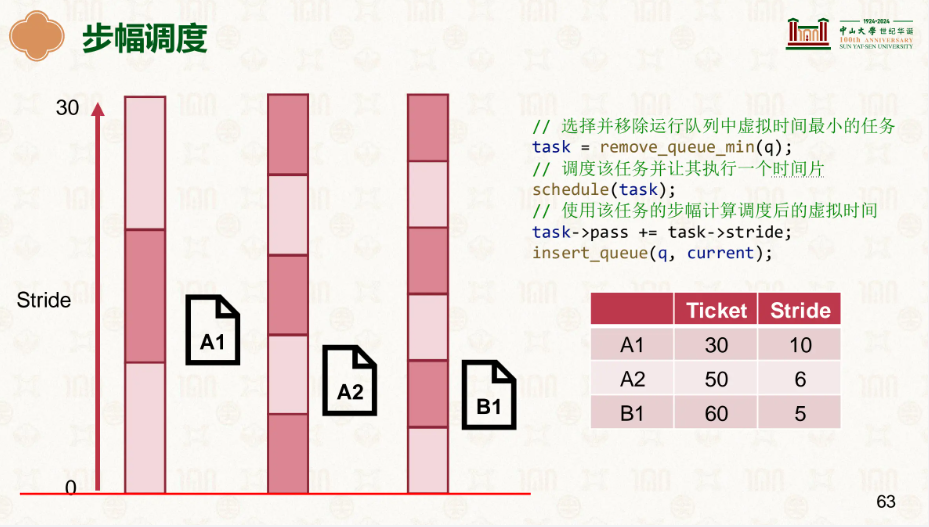
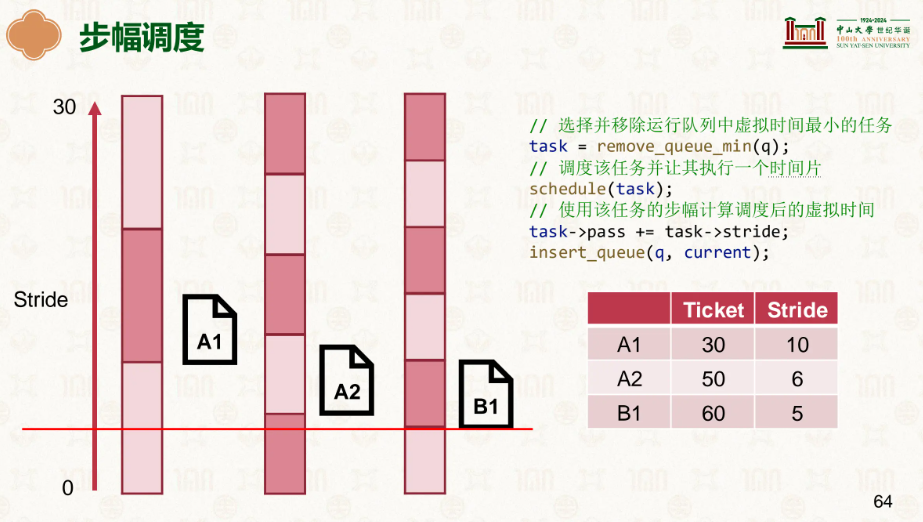
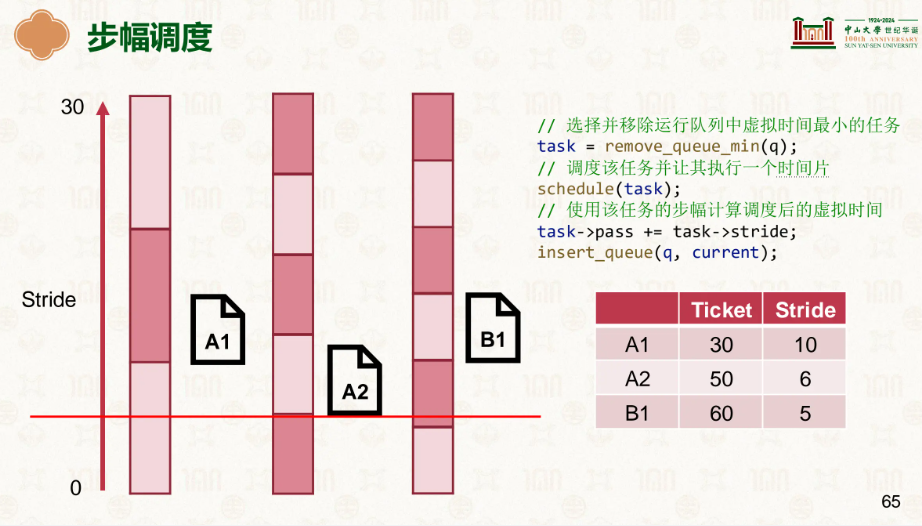
…
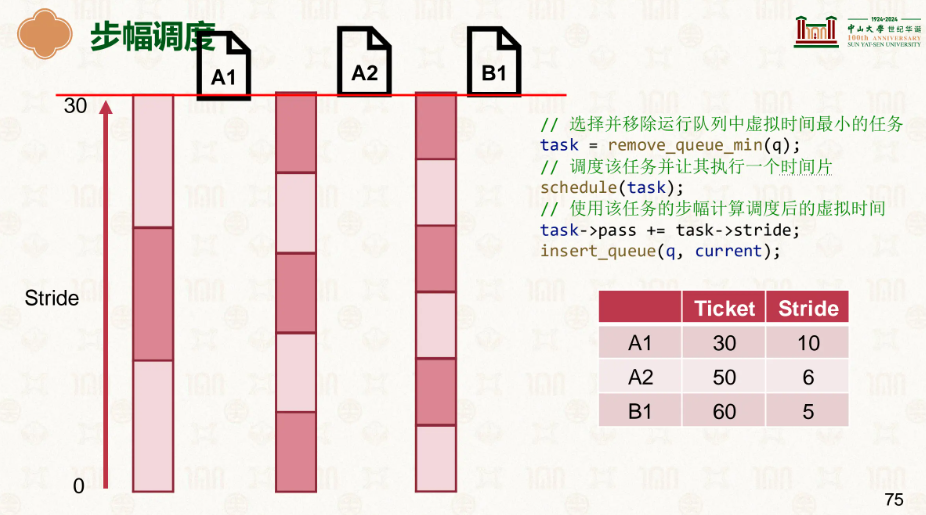
谁走的慢就踹谁屁股,这样很明显我们看到既没有随机的不稳定性,还能做到公平公正。

由此可见步幅明显更有,Linux也是这么认为的,在此基础上发展了更好的公平调度器运行队列。
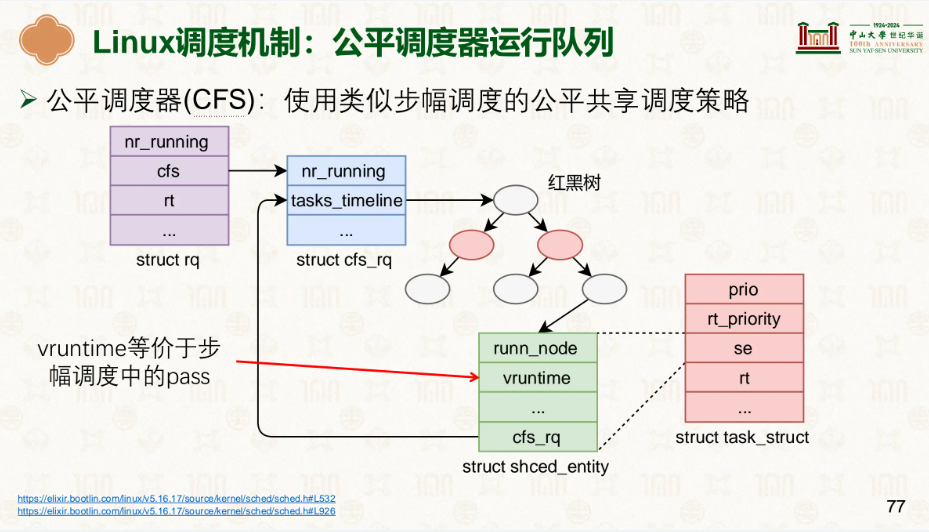
讲完了优先级、公平,接下来就是…
实时调度:
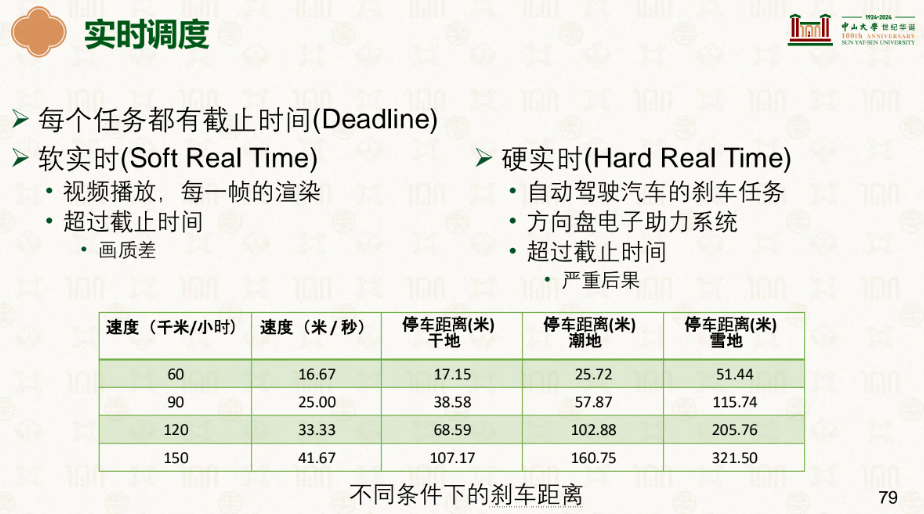
普通调度关心的是公平、吞吐量,而实时调度关心的是:每个任务必须在规定的截止时间(deadline)之前完成,否则就是失败。
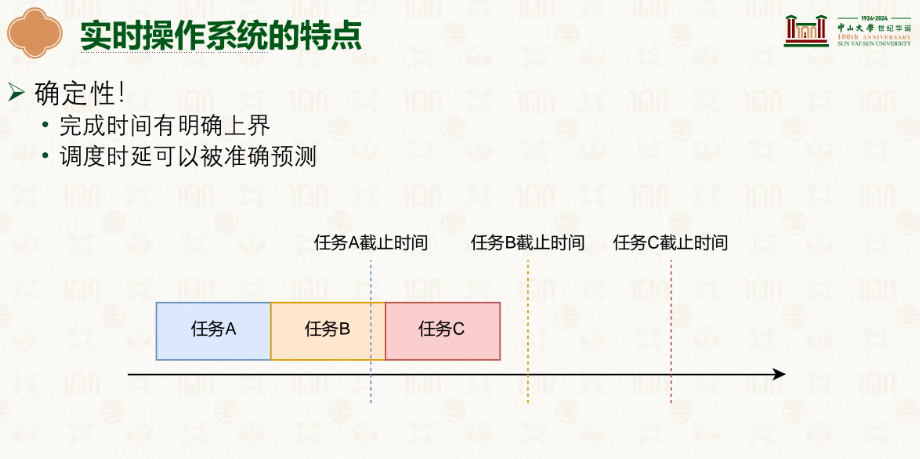
实时调度可以看作是每一个时间段都有自己要做的时候,如果你这个任务超时了就会影响其他的任务。
| 硬实时(Hard Real-Time) | 灾难性后果,绝对不允许超时 | 汽车刹车系统、航空控制、心脏起搏器 |
| 软实时(Soft Real-Time) | 体验降级,偶尔可以容忍 | 视频播放、游戏画面、音乐流媒体 |
视频播放(软实时)→ 每秒需要渲染 24/30/60 帧,某一帧没按时解码出来 → 画面卡顿/掉帧
游戏(软实时)→ 每 16ms 要算完一帧(60fps),超时 → 帧率下降、操作延迟
汽车系统(硬实时)→ 传感器检测到障碍物,必须在几毫秒内触发刹车 → 超时 = 车祸/人命
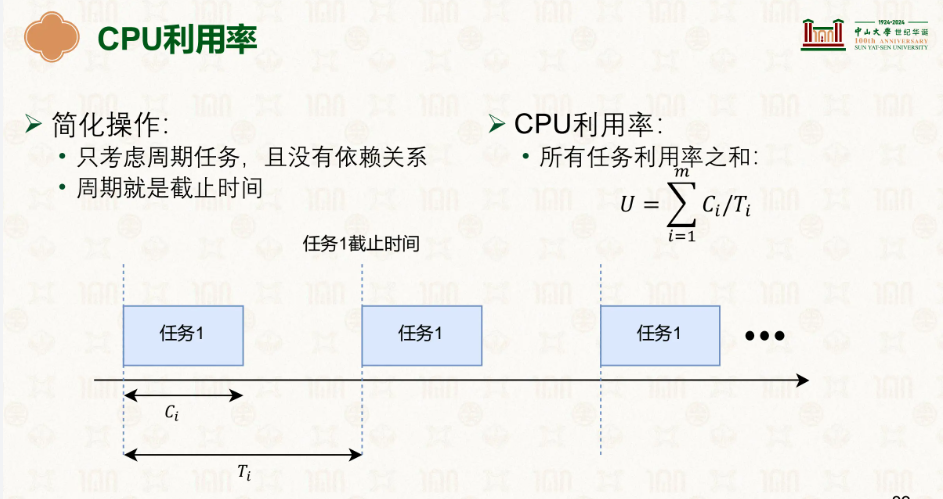
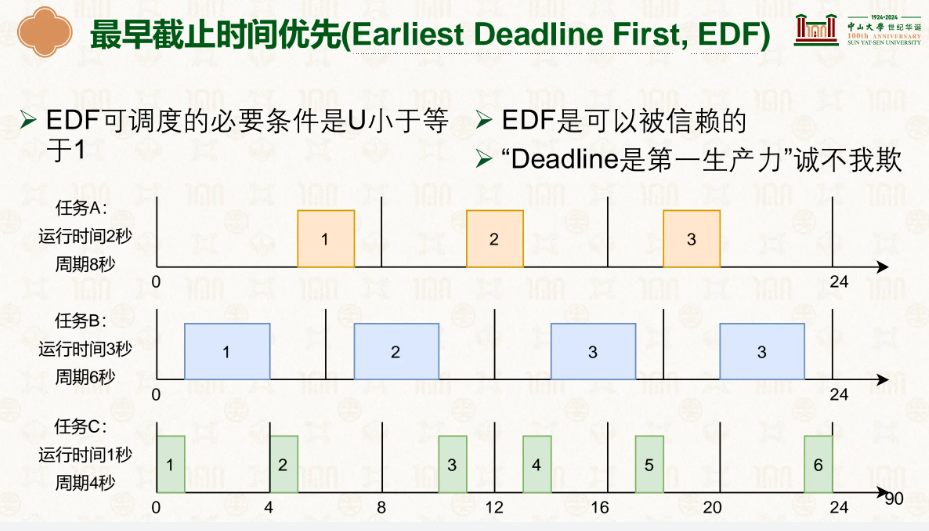
若要满足能这些任务能成功调度,必要条件就是U一定小于或等于1
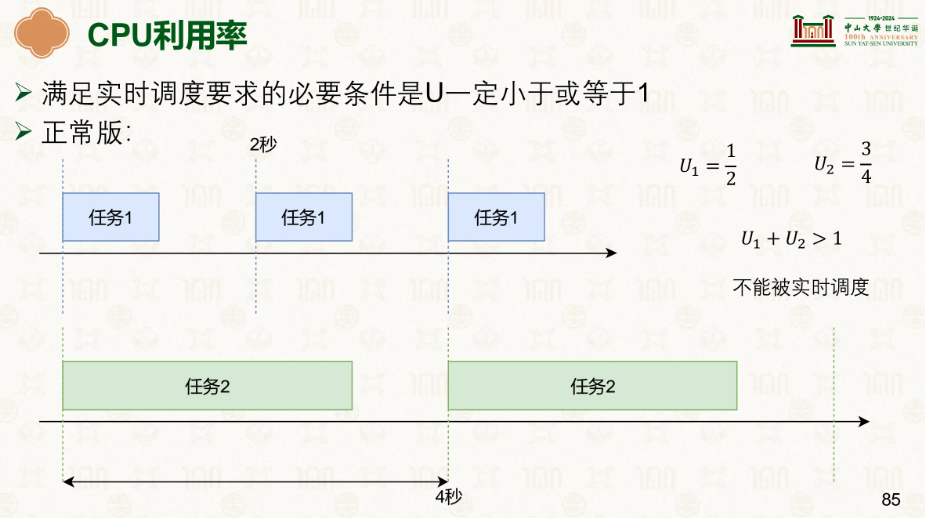
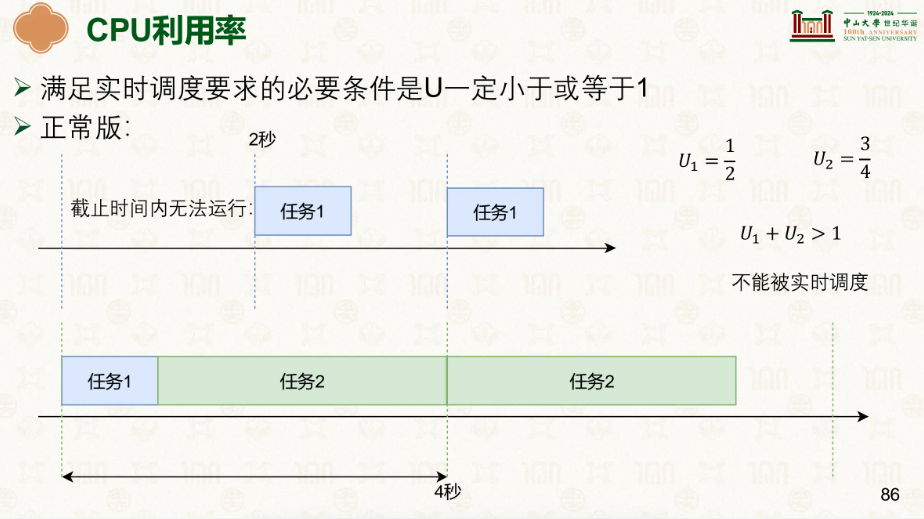
因此我们在实时调度上有了几个策略:
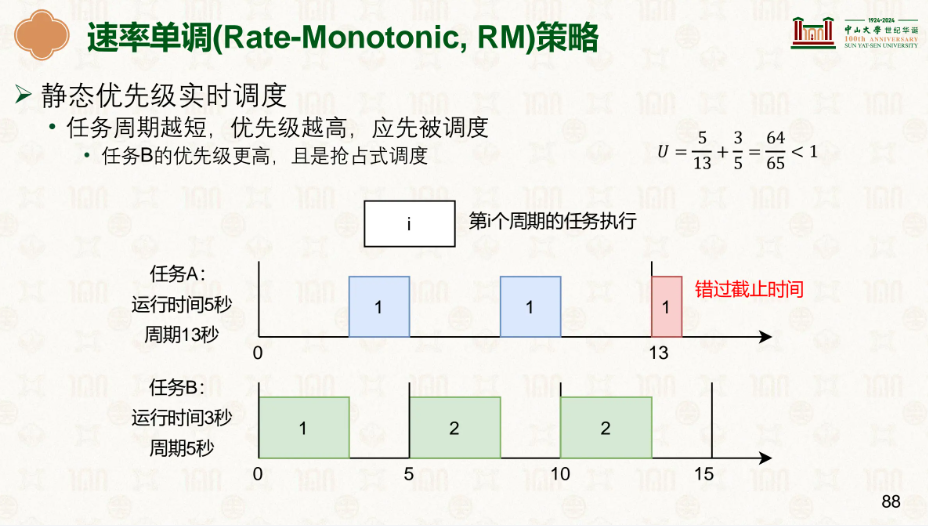
特点是谁的周期短,谁的优先级就高,优先级一旦分配就固定不变,并且是允许抢占的,也就是优先级更好的一转好就抢占掉执行他自己。
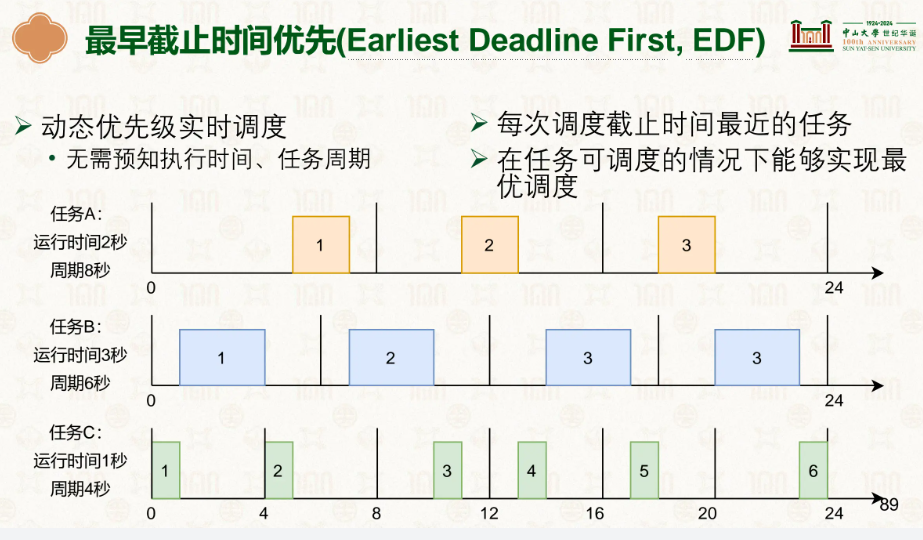
这应该算我们最熟悉的可,deadline优先,哪个快要截止了哪个先做,比如我们做作业,明天要交的先做,后天要交的先放放。
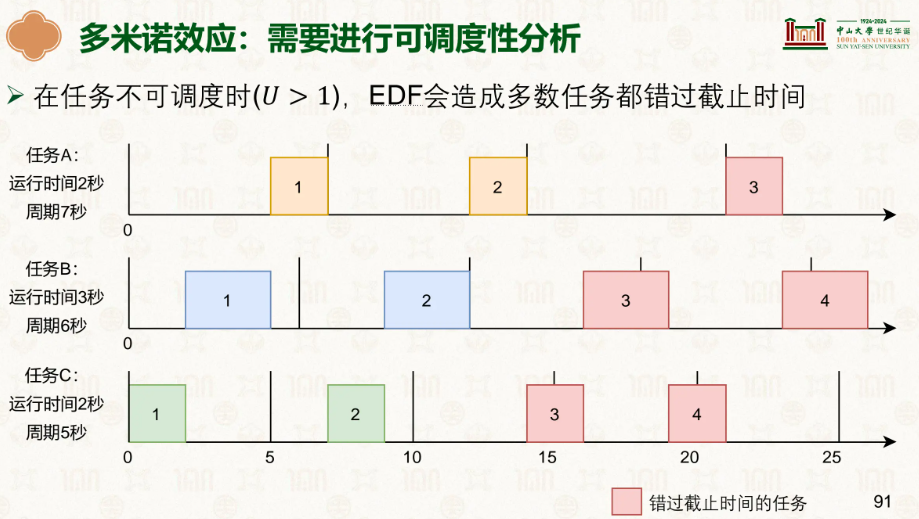
一旦出现任务不可被调度到正常执行时,就会出现一个任务超时而多个任务超时,这是 EDF 特有的缺陷,因为 EDF 是动态优先级,当系统过载时,它会不停切换去救快要超时的任务,结果导致连锁超时(多米诺效应)
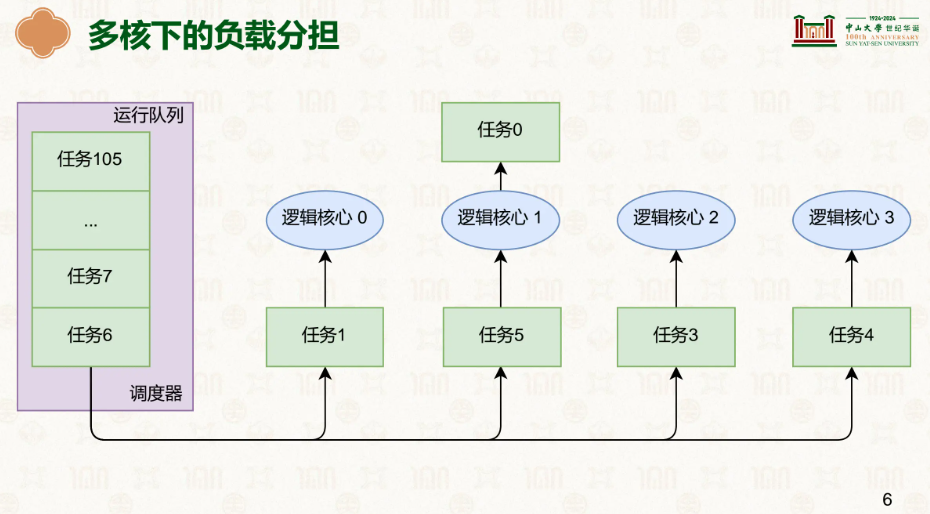
在多核情况下的调度,我们就为了避免一核有难,多核围观的情况:

因此在多核下,我们调度的主要目的是负载均衡,让每一个CPU功能工作而不是一个猛猛干别的看戏:
因此我们要探究下不同任务之间的关联性,探究该怎么做到合理的分配:

但我们也不好但凡存在前后关系就一个CPU干,这样效率太低了,因此引入协同调度,让没有依赖关系的并行,有依赖关系的等待别的工作完再继续:
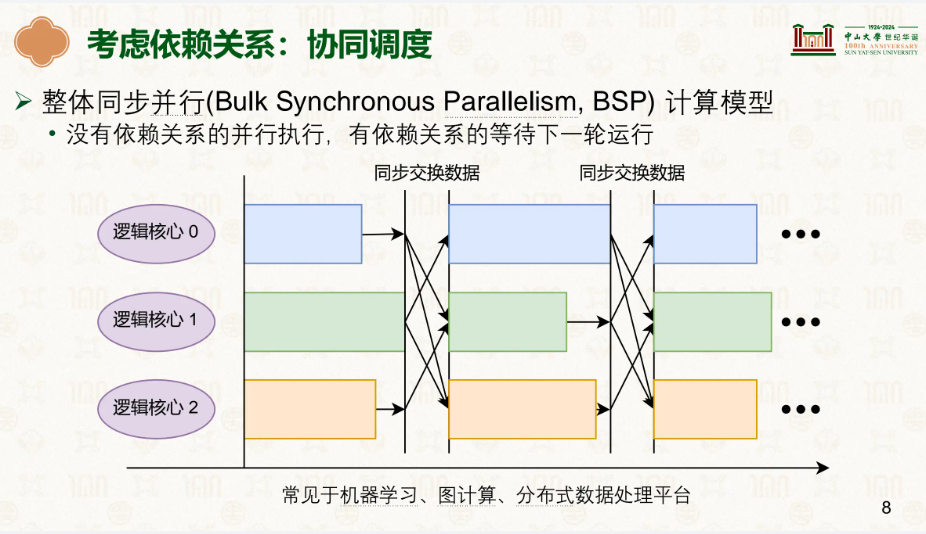
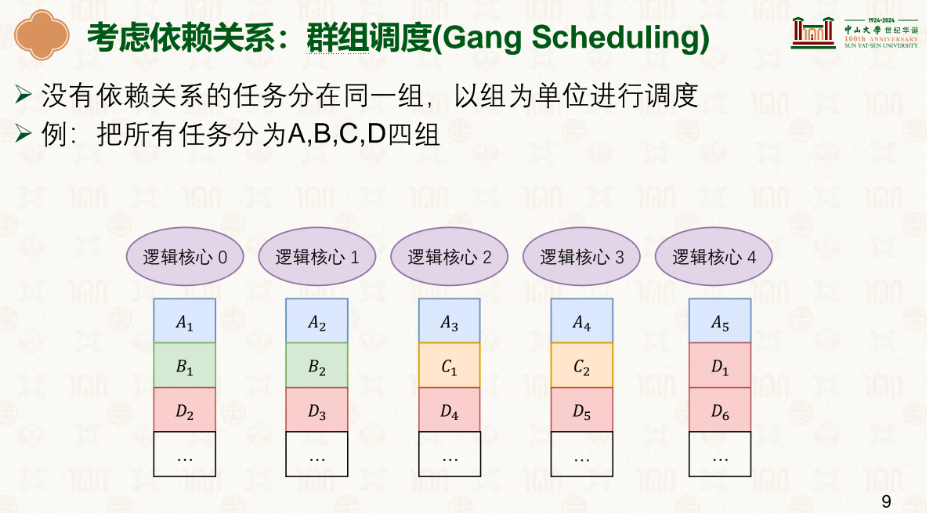
同时我们也能发现,如果前后依赖中,同一层级的不存在依赖,此时可以让同一层的并行,前后层同步,就是群组调度:
同时我们要考虑一个问题,毕竟CPU和硬件是物理的,所以需要考虑现实因素,不同的CPU有着自己的硬件,而同一个进程的线程可以在多个CPU上运行:
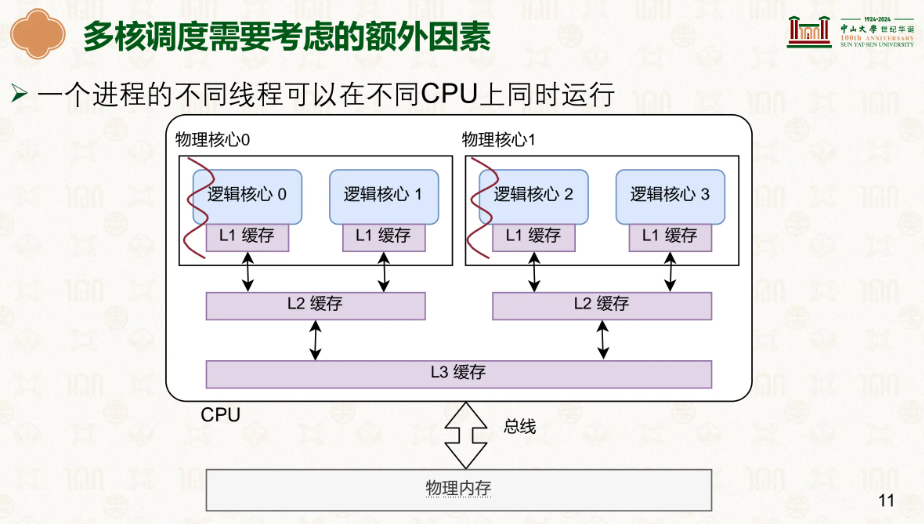
那么就能衍生出问题,线程切换的如果很频繁,会影响效率吗?答案明显是肯定的,如果同一个线程不断地在不同的CPU上工作,缓存中数据就需要重新从内存中拉取然后存入缓存,会大大的降低效率。
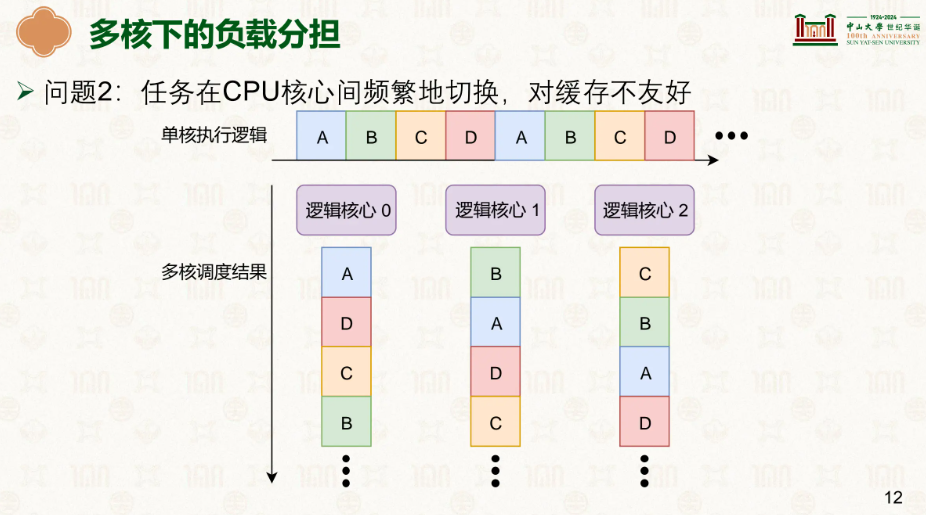
为此我们需要进入一个对缓存更加友好的调度:
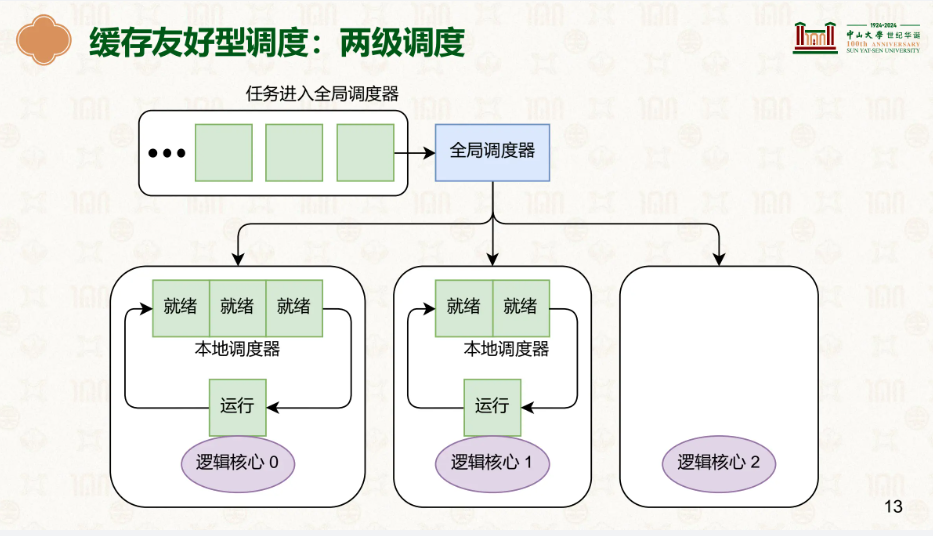
两级调度(Two-Level Scheduling)
两级调度是一种缓存友好的多核 CPU 调度策略,它调度分为两层,减少进程在不同核心之间迁移导致的缓存失效,全局调度器负责分配不同的任务到某个核心,而本地调度器调度任务,尽可能地减少一个任务在一个CPU工作一会就跳去另一个工作,以减少缓存miss。
但同时两级调度也存在着它的问题,指定线程在某个CPU上运行容易负载不均衡,因为本地调度的只是本地的线程,若是全局调度不太好,就会出现某个核心有着很多任务而别的核心却在发呆。
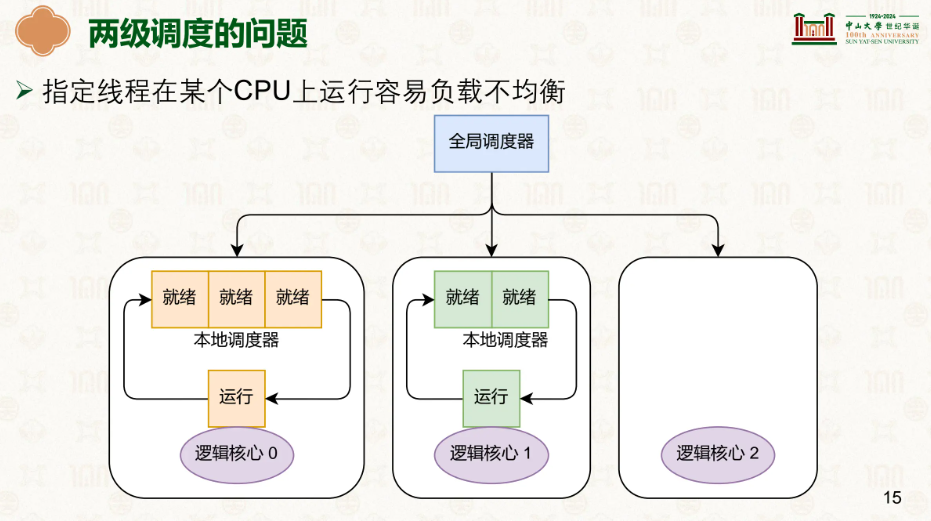
因此我们引入负载均衡来衡量某个核心的压力,如果某个核心压力过大,同时存在核心过于清闲,我们便能进行调度,将一部分任务交给另一个核心,虽然会导致部分的缓存miss,但总体上还是提高了效率。
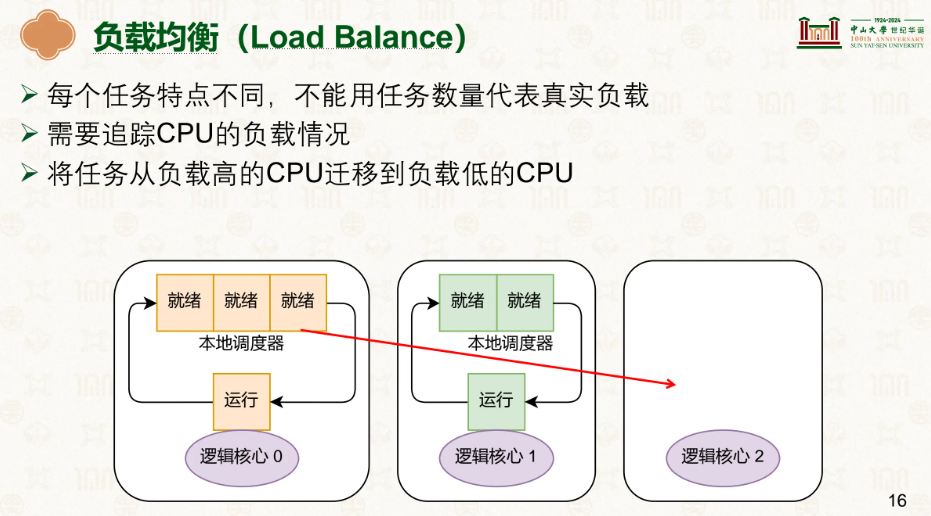
但我们也不能简单地通过任务队列有多长来判断负载重不重,假设一个核心有很多个任务,但每个任务只需要工作几秒,另一个只有一两个但每一个都需要工作数小时,因此简单的队列长度是不合适的。

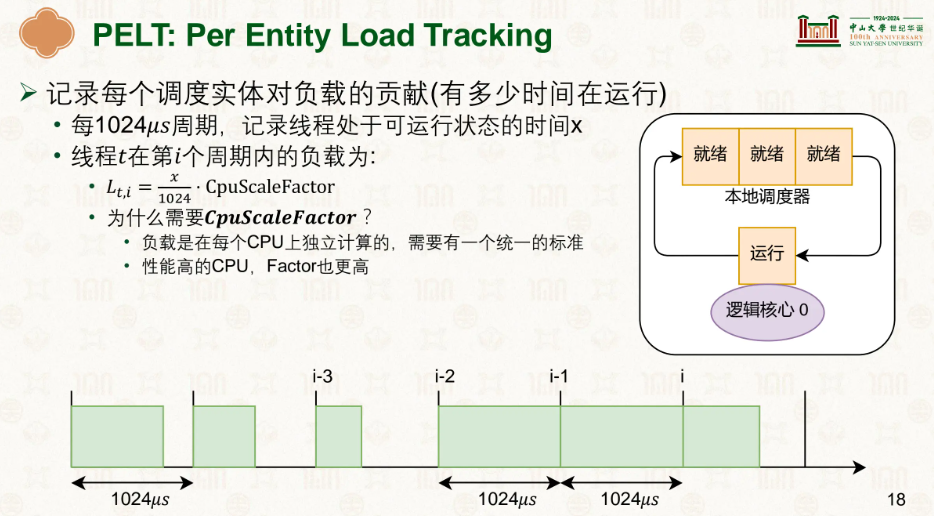
我们引入了 PELT 来观察负载情况,PELT 将时间切分为一个个 1ms(1024μs)的周期,每个周期观察任务的状态:
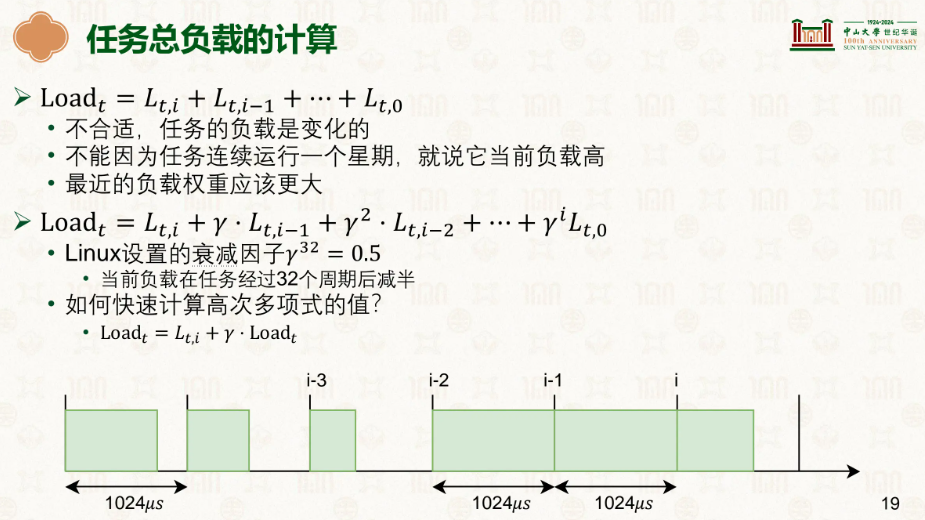
我们对每个工作区间做了多久 * 时间衰减因子,离得越远的状态影响越小,同时观察任务状态,分为
| 状态 | 含义 |
|---|---|
| Running(正在运行) | 占用 CPU 执行中 |
| Runnable(可运行但等待) | 在就绪队列排队 |
| Sleeping(睡眠) | 不贡献负载 |
通过三个指标衡量CPU的状态:
| 信号 | 计算范围 | 含义 | 用途 |
|---|---|---|---|
util_avg | Running 时间占比 | CPU 实际被利用了多少 | DVFS 调频:决定 CPU 该跑多快 |
runnable_avg | Running + Runnable 时间占比 | CPU 的竞争压力有多大 | 负载均衡:判断核心是否过载 |
load_avg | runnable 占比 × 任务权重(nice) | 带优先级加权的负载 | 负载均衡:高优先级任务贡献更大负载 |
举个例子:
核心 0 时间线:
Task A: ████░░░░████░░░░ (运行50%, 等待50%)
Task B: ░░░░████░░░░████ (运行50%, 等待50%) ────────────────CPU: 始终 100% 占满| 指标 | Task A | Task B | 核心 0 汇总 |
|---|---|---|---|
util_avg | ~512 | ~512 | ~1024 (满载) |
runnable_avg | ~1024 | ~1024 | 存在竞争压力 |
util_avg看起来 CPU 刚好满载,但runnable_avg暴露了两个任务在互相争抢,这就是”压力”信号,可以找一个清闲的CPU分个任务过去让这个CPU竞争压力小一点。在有些时候,老程序员比内核更知道他自己的程序应该怎么调度能发挥更好的性能:

我们引入了处理器亲和,设置了亲和的线程会更倾向于在对应的CPU上运行。









