
有了对内存的基础认识,我们终于能进入到进程、线程的世界。
在早期,操作系统还在混沌之中,或者说,并没有形成操作系统的概念,此时程序直接与硬件进行交互,由此可见,因为没有操作系统的中转带来的延迟,效率相对还是较高的,但是,危险性也高,一个弄不好就会导致信息泄露、硬件故障等。
同时人们还处于程序加载、执行、结束的过程,也没有多种程序之间的切换,可以理解为只有一个进程在跑,跑完就结束,等下一个进程加载,没有中途切换进程的功能。
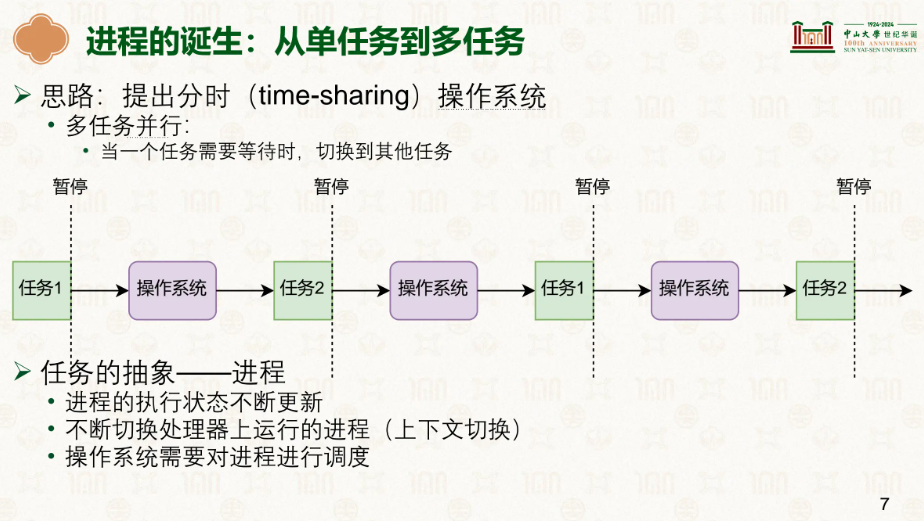
慢慢的,随着硬件的发展,内存的大小变大了,此时,cpu拥有了切换进程执行的能力,可以执行进程A一段时间后切换到进程B,同时因为硬件IO过慢,CPU的效率过剩的问题,开始引入了中断,在进程A触发IO操作等待时,可以切换到进程B进行,这是一次效率的飞跃,也是进程管理的出现。
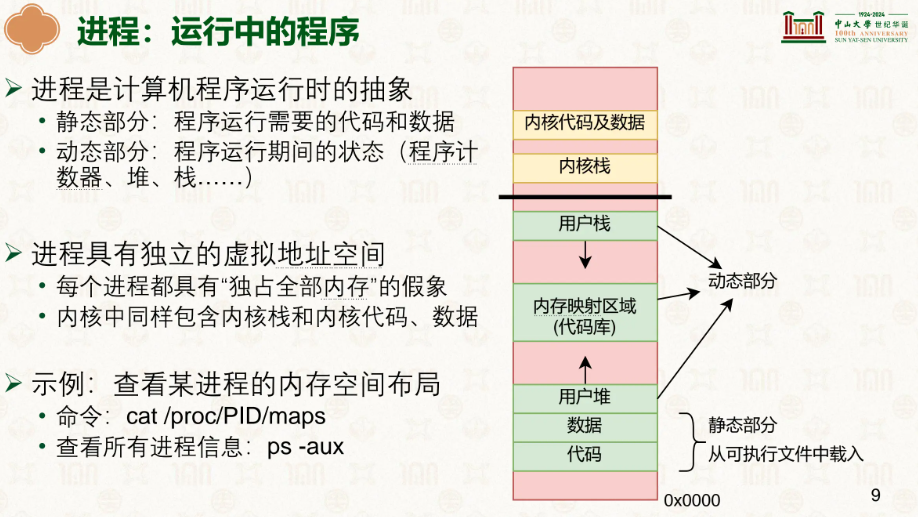
进程的上下文有什么,我们熟悉于栈、堆等,而进程创建时,他们所需的各个信息又是从ELF(可执行性文件)中获取。
ELF里包含着大量信息:

我们创建进程需要load ELF,将ELF需要加载时,读取ELF的头部,接着解析程序头部表。
然后按段(Segment)映射到虚拟内存中,接着设置栈和寄存器上下文,如有动态链接库则链接上。
ELF头部:
魔数:0x7f ‘E’ ‘L’ ‘F’(这里的 char 是ASCII码,用来确定这个文件是ELF文件)
e_type(可执行文件 / 共享库 / 目标文件)
e_machine(需要在什么架构下运行(x86、ARM 等))
e_entry(给PC的,指令执行的入口)
e_phoff(程序头部表在文件中的偏移)
e_phnum(程序头部表中有多少个条目)
程序头部表(Program Header Table),指示文件的哪一块内容,应该映射到内存的哪个地址,权限是什么,每个条目(Program Header)描述一个 段(Segment)。
类型: PT_LOAD ← 需要加载到内存的段
文件偏移: 0x0000 ← 从文件的哪里开始读
虚拟地址: 0x00400000 ← 映射到进程的哪个虚拟地址
文件大小: 0x1A00 ← 文件中占多大
内存大小: 0x1A00 ← 内存中占多大
权限标志: R-X ← 只读+可执行(代码段)
然后按段映射到虚拟内存,内核用 mmap 将段内容映射到进程的虚拟地址空间,接着设置栈和寄存器上下文(SP、PC),堆则在运行时由 malloc/brk 按需增长,这样一个进程就初始化完成了。
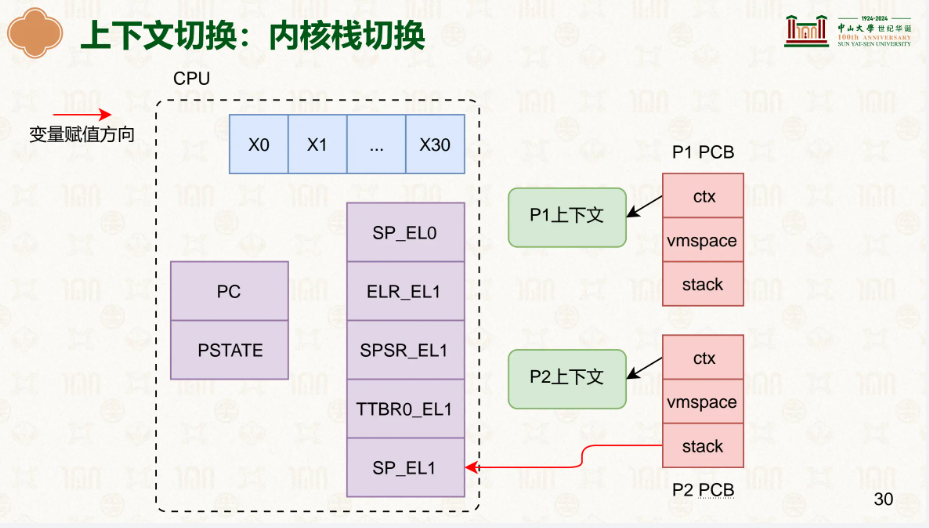
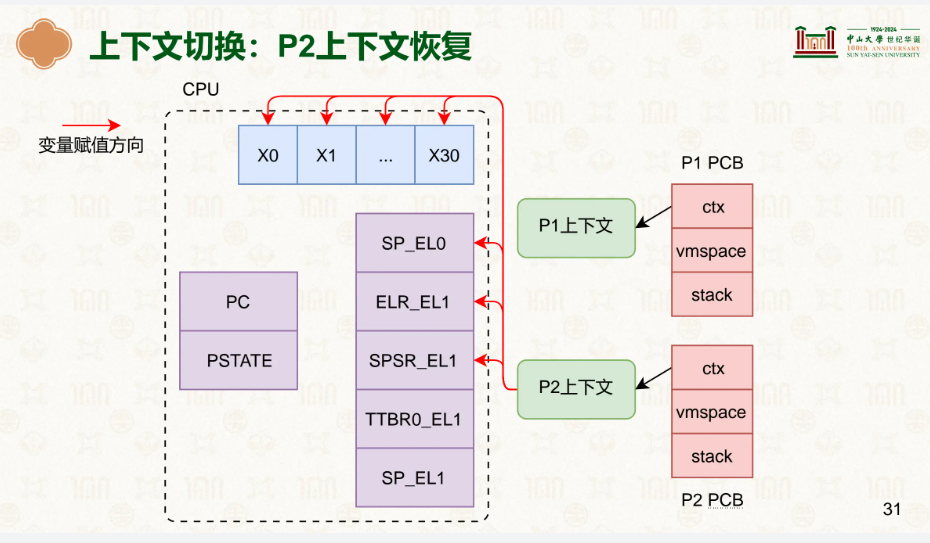
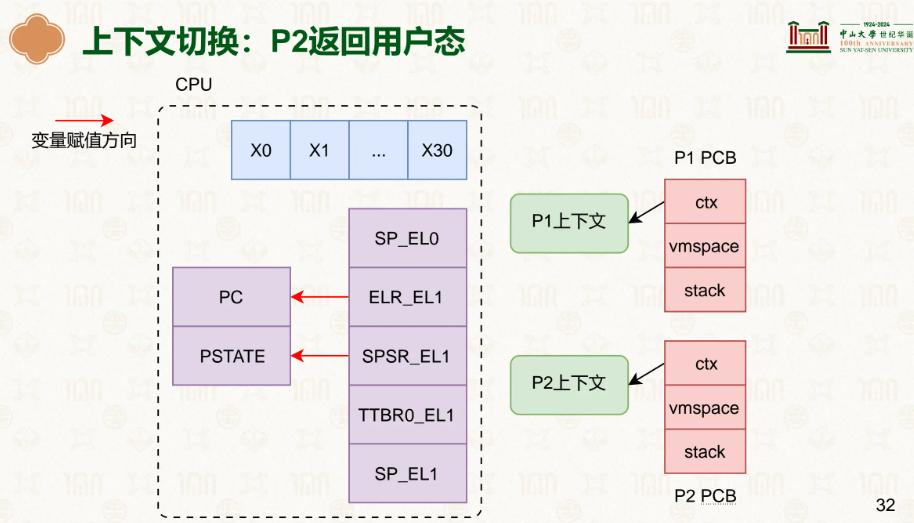
而进程的上下文包括什么?各种寄存器,记录着它执行到了哪里、储存了哪些东西:
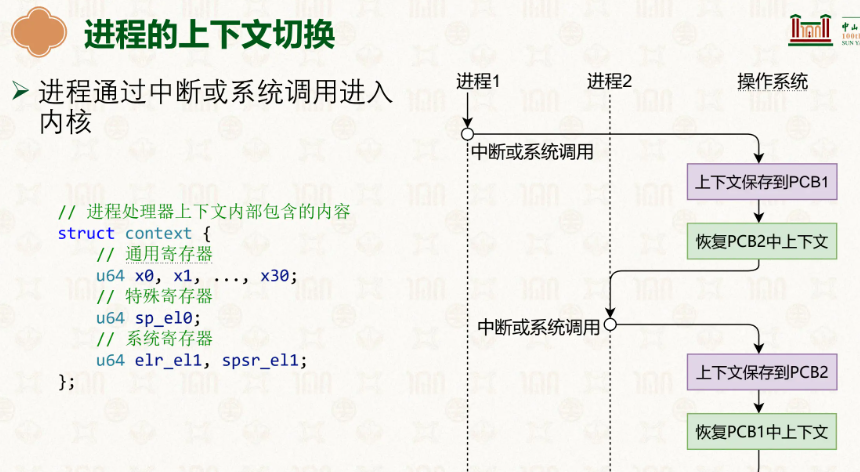
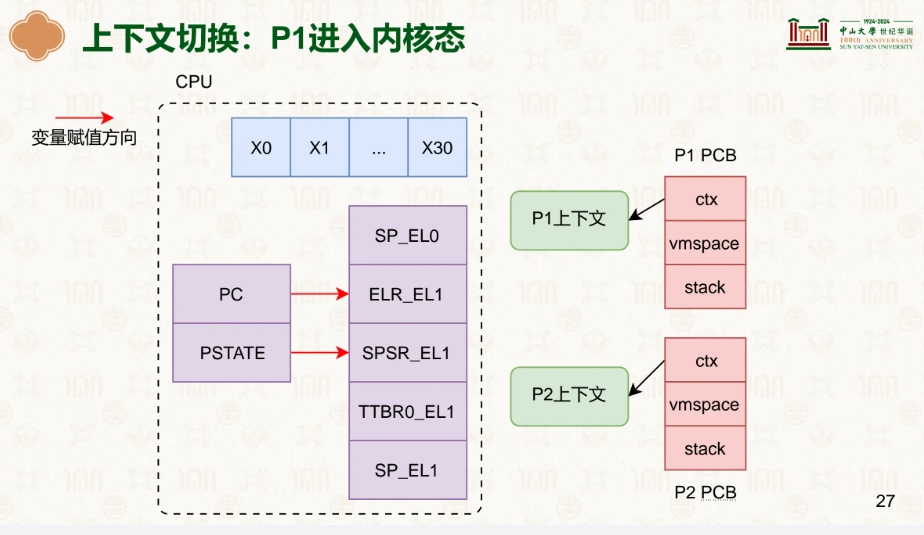
通用寄存器很好理解,sp_el0为栈指针的位置,elr_el1是在之后再次切换上下文切换回来,el1->el0时往PC里填的,因此这里我们要放发生中断时PC寄存器里的值,这样恢复回来可以继续执行,spsr_el1是当时PSTATE的状态,PSTATE 是处理器状态寄存器,其中的条件标志位(N/Z/C/V)会在 ALU 计算后更新,记录结果是否为零、是否溢出等,但它还包含中断屏蔽、异常级别等信息。
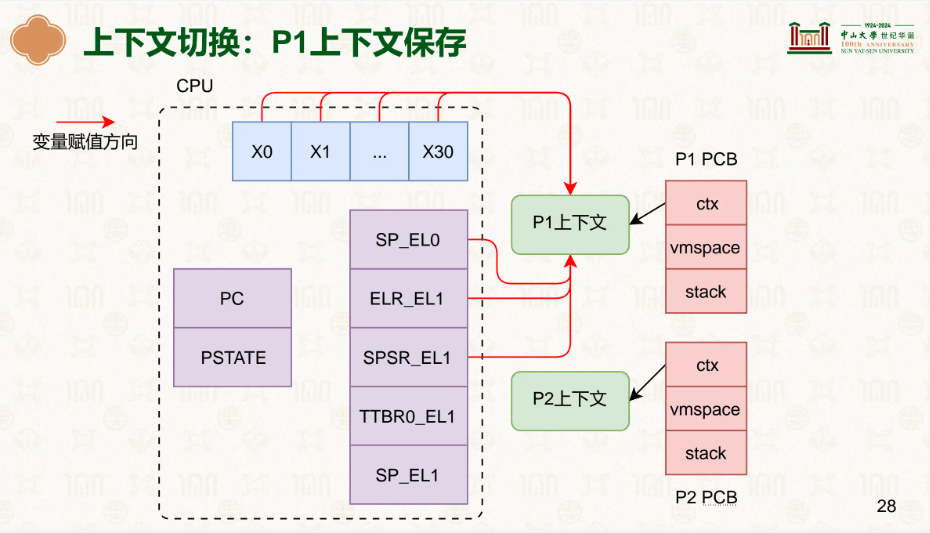
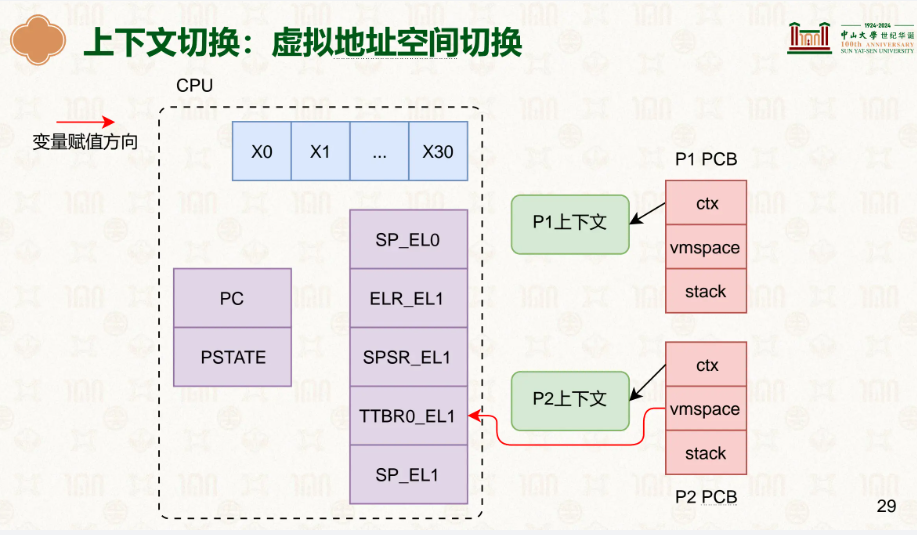
ctx就是我们所说的寄存器等的上下文,vmspace你可以理解为整个虚拟地址空间,里面有着各种vmregion,TTBR0_EL1就是储存着页表基地址的寄存器,stack是内核栈而不是用户栈,内核栈是该进程在内核使用的栈。
关于进程的基础操作我感觉在CSAPP的学习中差不多都知道了。

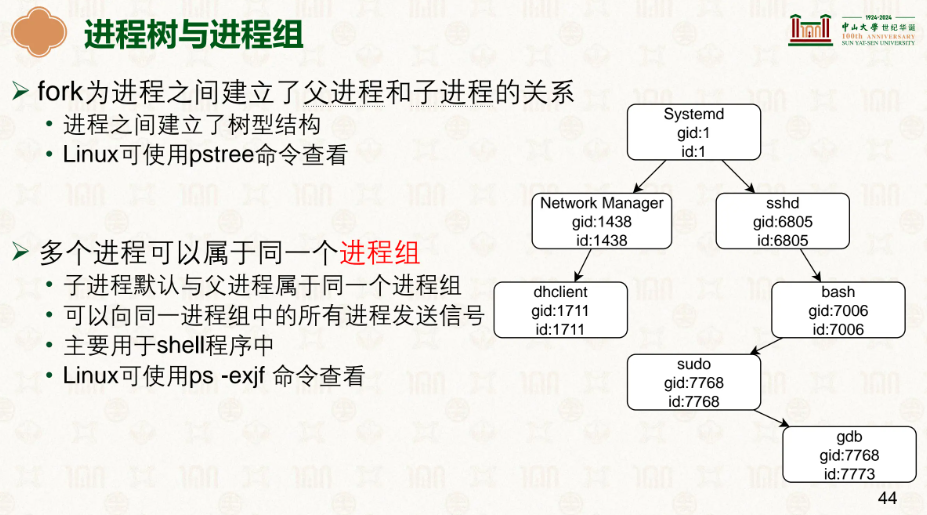
fork在当前位置fork一个子进程,两者有着相同的上下文等

而进程也有进程组(pgid),默认的fork,子进程会继承父进程的pgid,多个进程可以在同一个进程组下,我们可以对一个进程组发送信号,比如kill,这样假设一个pgid代表WordPress,我们可以往这个pgid发送kill让该组的进程全死翘翘,而不是费劲巴拉的一个个看过去找哪些进程是属于WordPress的,然后一个个kill。

exec,将该进程的上下文改为目标行为所需的上下文

waitpid,执行时需要等待目标进程结束,执行该waitpid的进程才能继续进行。

然后是进程的状态:
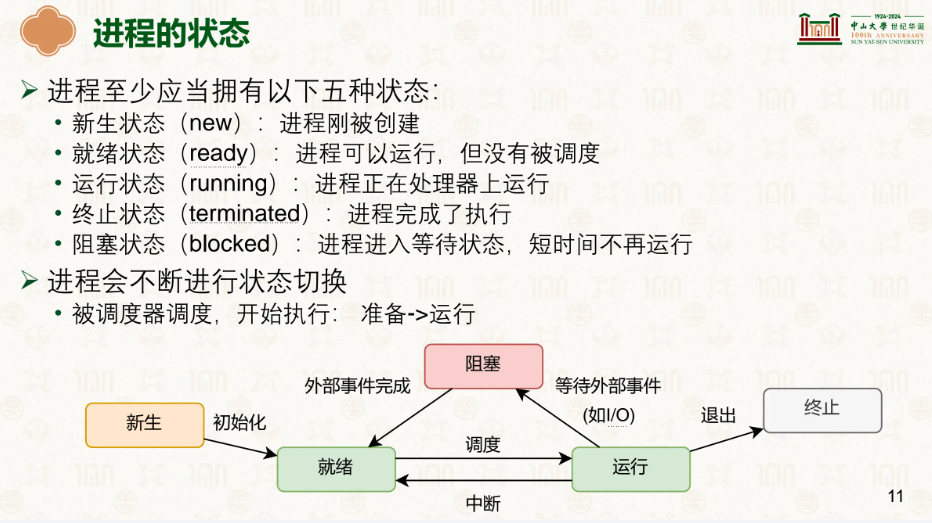
除了刚创建的进程和离开的进程,其他时候进程都在中间的三个状态徘徊。
新生很好理解,刚刚被创建,等初始化完成就进入就绪,等待被调度,在运行的时候等待IO操作时,变为阻塞等待IO完成,或发生调度从运行变成就绪,直到进程的使命终结然后离开。
通过上面,我们很明显能看出进程过于重,每一次fork都需要完整的复制上下文,虽然独立性很强,但很多情况下,我们并不需要这么强的独立性,有时需要通信的任务,通过进程间通讯(IPC)会带来更多的负担,同时一个进程只能执行一个任务,没法进行多任务的并行。

线程的诞生了,更轻量化的切换、更小的负担,可以并行执行,但也带来了竞争。


线程不像进程,是独立的内存空间等,一个进程可以有多个线程,同一进程的多个线程共享代码段、数据段、堆等内存空间,但每个线程有自己独立的栈和寄存器上下文,也就是说,他们是共享一大块内存空间的,这样进行通信就很简单,在对方那里写就能收到,但是,也正是因为这样,竞争就会很激烈。

用户态线程(纤程、协程)对内核不可见,而内核可见的线程才能被内核调度,可以这么看,内核可见线程就是内核可以调度的线程,内核不可见线程是其他进程自己的线程,虽然内核管理者其他进程,但这些进程的线程它不管,我附庸的附庸不是我的附庸:
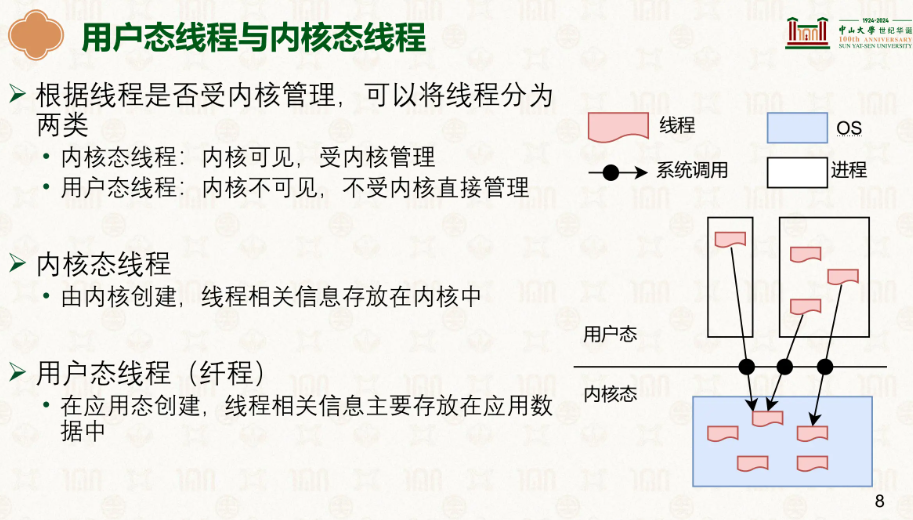
我们首先要明确,用户态的线程内核不知道,只有内核可见线程才能真正被 CPU 调度运行,用户线程想要运行,必须”绑”在某个内核可调度线程上,才能获得 CPU 时间,因此我们分了多种形式:
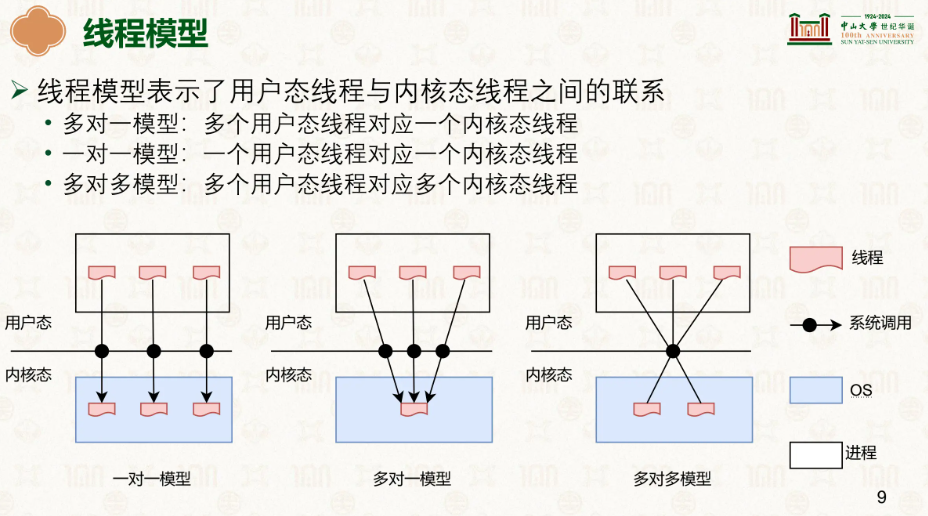
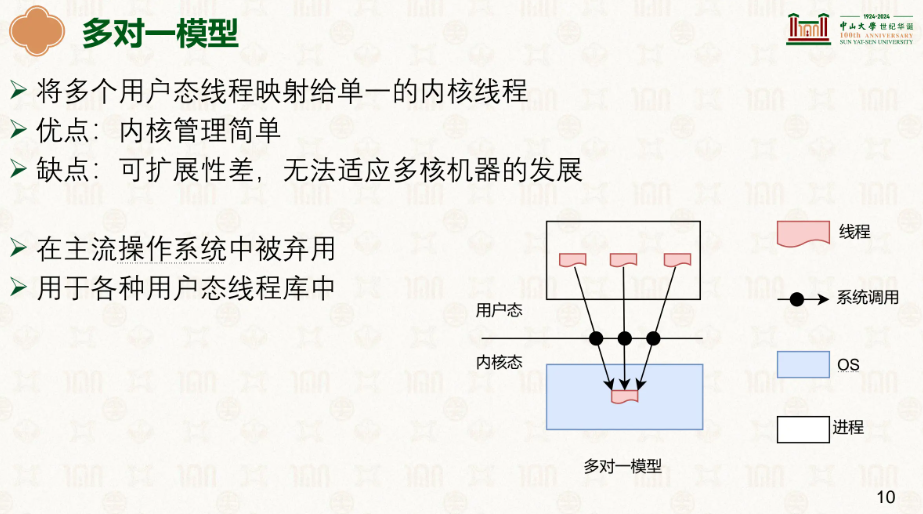
在多对一模型中,内核分配这个进程到CPU的一个核心并允许他能执行10ms,然后进程让进程自己跑,至于怎么跑的不管他,是进程自己做事还是分配线程,有进程自己决定,但这样是没法并行的,因为这只是在一个核心上。
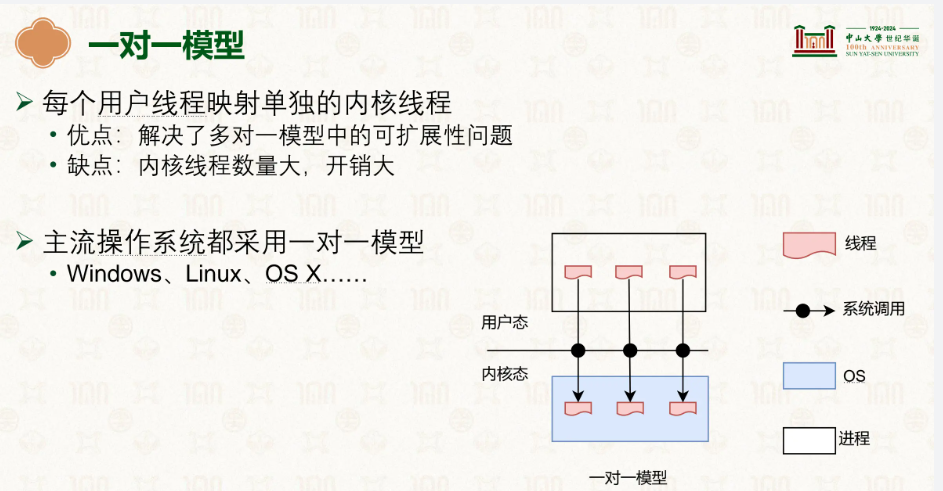
而现在大多是1对1模型,你可能疑惑,内核不是看不到用户态的线程吗,这又怎么做到一对一呢?在该模型中,创建用户线程的同时,内核同步创建一个真正的内核可调度线程,两者一一绑定,是同一个东西的两面,在用户态,该线程表现为 pthread 结构体,在内核态则对应一个 task_struct,然后让内核进行调度,就能同时在不同的核上执行任务,此时就能做到并行了。
多对多模型用在:需要大量逻辑并发(用户线程/协程数 > 内核线程数),同时希望避免“多对一”模型中的单点阻塞问题,又不能接受“一对一”模型创建过多内核线程的开销,典型如早期高并发服务器、自定义协程库、Go语言运行时。

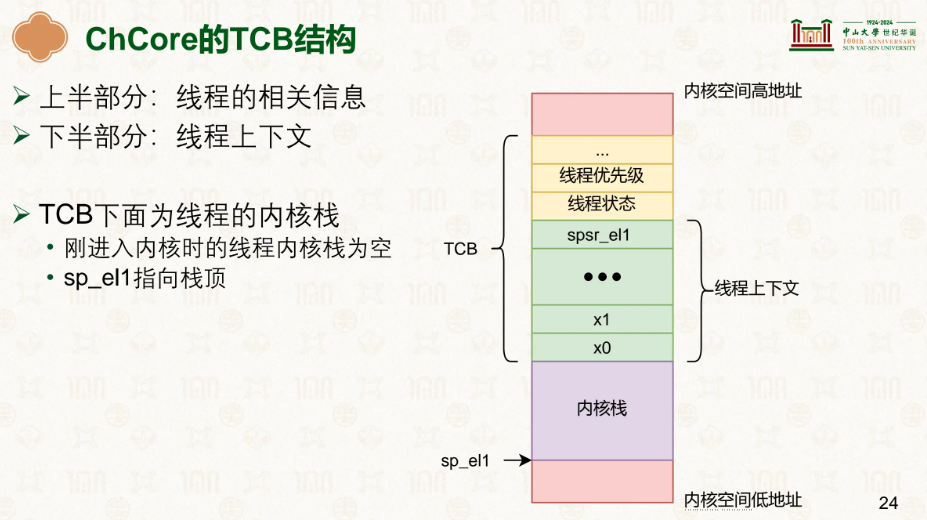
TCB = Thread Control Block(线程控制块)
在线程创建的时候会动态的根据大小在内核区域预留一块空间,这个空间就是给线程保存上下文用的。
就是线程版的 PCB。PCB 记录进程的信息,TCB 记录线程的信息。
一个TCB里有内核态的部分和用户态的部分,
内核态分为线程id、寄存器、内核的栈指针等。
用户态分为用户栈指针、pthread_t等
或许你可以把它理解为该描述该线程的所有信息。

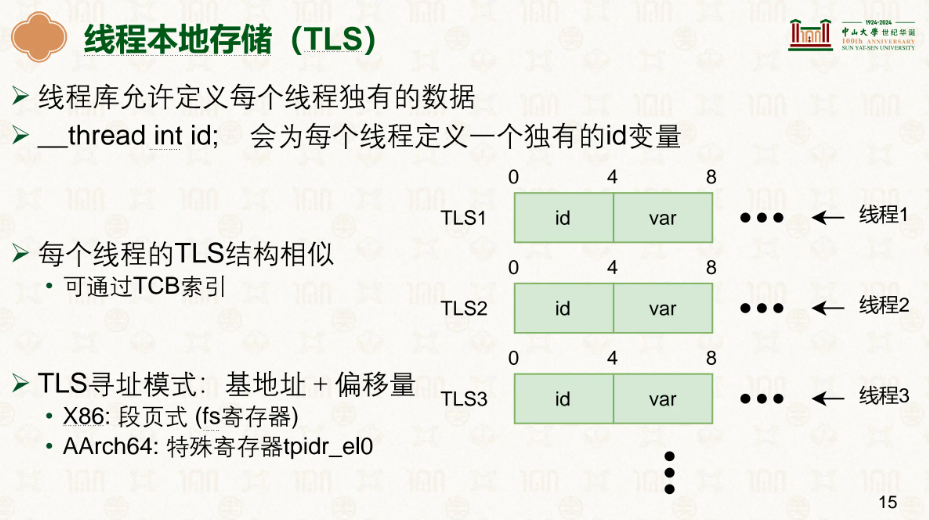
TLS是线程本地自己的,前面讲到他们共享一个内存空间,
TLS 是一种机制,让同一个全局变量在每个线程中拥有各自独立、互不干扰的副本。 每个线程对该变量的读写,只影响自己的那个副本,不会影响其他线程。
举例:
#include <stdio.h>
#include <pthread.h>
// 声明一个线程局部变量
__thread int tls_var = 0;
void* thread_func(void* arg) {
int id = *(int*)arg;
tls_var = id * 100; // 写入自己的副本
printf("线程 %d: tls_var = %d, &tls_var = %p\n",
id, tls_var, &tls_var);
// 模拟一些工作...
sleep(1);
printf("线程 %d: 再次读取 tls_var = %d\n", id, tls_var);
return NULL;
}
int main() {
pthread_t t1, t2;
int id1 = 1, id2 = 2;
pthread_create(&t1, NULL, thread_func, &id1);
pthread_create(&t2, NULL, thread_func, &id2);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
// 主线程的 tls_var 还是 0(初始值),不影响
printf("主线程: tls_var = %d\n", tls_var);
return 0;
}__thread 这种 TLS 在底层是怎么做到”每个线程一个副本”的?答案是靠一个专用寄存器指向当前线程的 TLS 区域:x86_64 上是 FS 寄存器,ARM64 上是 TPIDR_EL0。线程切换的时候这个寄存器也跟着切
然后就是线程的一些基础操作:
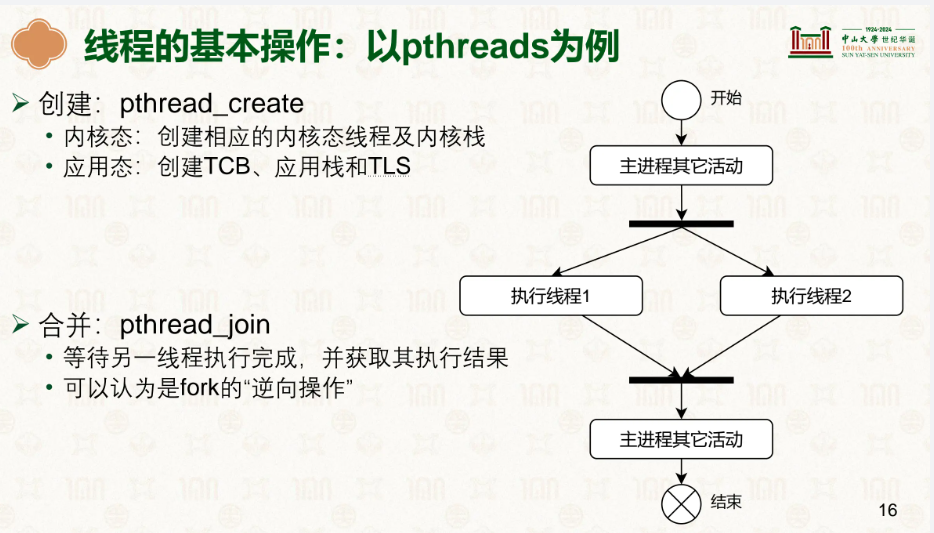
pthread_create就像进程的fork一样,是创造一个子线程,而pthread_join,类似waitpid,等待该线程结束。
以及一些别的操作如pthread_exit,当前的线程退出掉,pthread_yield,当前线程暂停让出资源等待下一次调度。


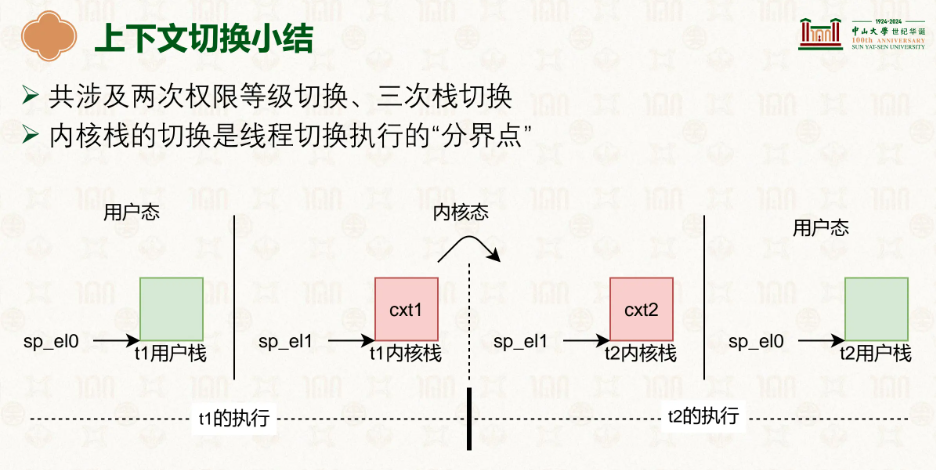
当线程发生调度切换时,我们想想他们的上下文有什么,寄存器、栈指针、PC和PSTATE,线程不像进程相互独立,在共享的内存空间里,线程切换时不需要切换页表(TTBR0_EL1)、代码段、数据段、堆等,因为这些是共享的,因此我们只需要保存工作相关的信息即可。

当切换上下文时,将当前线程的寄存器上下文保存到该线程 TCB 的 ctx 字段中,等待下次调度然后恢复。





纤程或者说协程,也是go语言go去执行的玩意。


还记得上面说线程保存的上下文是寄存器、PC和PSTATE那些吗?如果我们人为的设置好寄存器等相关的配置,getcontext就好像存档一样把这个状态存下来,但保存的只是自己的状态,对于全局变量、堆等部分,不在它保存的范围里就不受到影响,等执行一段时候你setcontext读档,不就恢复到刚开始执行的那时候了吗。
getcontext / makecontext 保存寄存器,它不会复制栈的内容,所以我在位置A存档,再在位置B存档,位置A在位置B的前面,假设它们在同一个栈上,我们读档A,A自己走走走,写到了位置B的PC指向的地方,此时就会出现污染,如果读档位置B,就发生了污染,因此协程要有自己的栈,避免交叉干扰。

如图让一个线程承载两个协程(生产者 + 消费者)
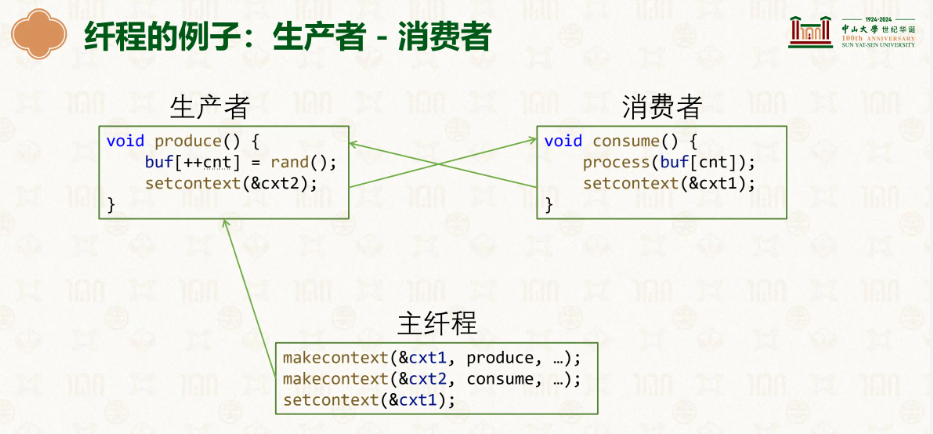
我们这里makecontext,做了两个存档,第一个存档是生产者刚开始执行的时候,另一个是消费者刚开始执行的时候,因此到这里到setcontext时,生产者开始工作然后读档到消费者,由于它更改的是寄存器那些,不会对buf产生影响,他就能自己玩了。










