
在聊完了虚拟地址,物理地址就要开始深入了解了。
在使用中,我们通常成将内存抽象成一个大数组,但实际上肯定不是的,内存是个物理硬件怎么会是简简单单的数组。
在CSAPP的学习当中,我们学过内存,你是否还记得内存的行缓冲区和缓存行的区别?让我们借此机会一起回忆和深入一下:
一个内存条有多个芯片,每一个芯片都有多bank,读取数据就是从bank中特定的row、col获取。
以下以DDR4 x16 为例,一个内存条有 4 个芯片,每个芯片里有多个bank,芯片类型有很多,如x4、x8和x16等,这里的x16代表内存的针脚数,也就是一次性能读取多少bit,x16代表一次能读取16bit,现在常见的内存总线一次传输可以传64bit,也永远传输64bit,也就是说不管你写入、读取都是64bit的形式,若是不满则根据需要读取、写入需要的部分:
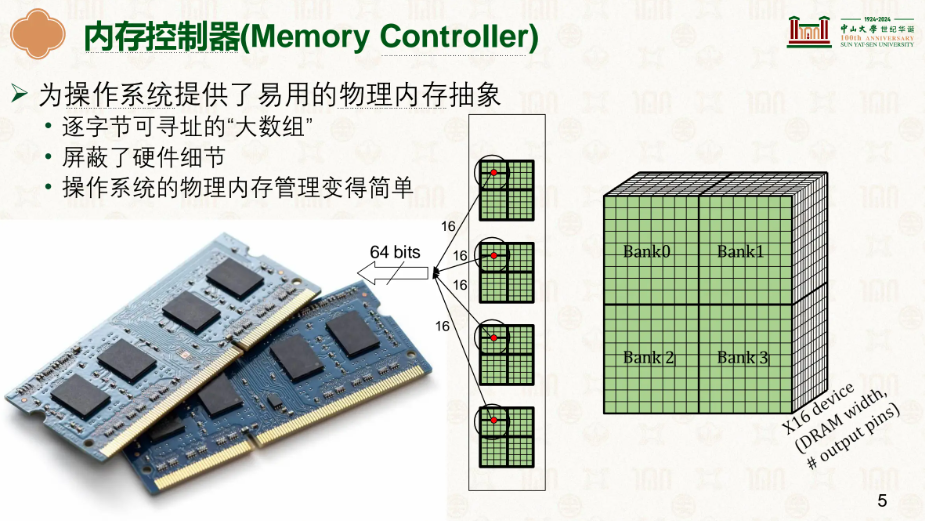
你可能会有疑惑,为什么要从每一个芯片读取16bit,而不是一个芯片直接读取64bit,答案其实很简单,增加芯片针脚的代价是很大的:更大的芯片封装(物理尺寸变大)、更多的 I/O 驱动电路(功耗增加)、更复杂的布线(信号干扰变严重)、制造成本显著上升等。
如果真的做了x64的,效果也不会很好,集中在一个芯片,如果这个芯片出问题了就完蛋了,同时功耗发热等也会很严重。
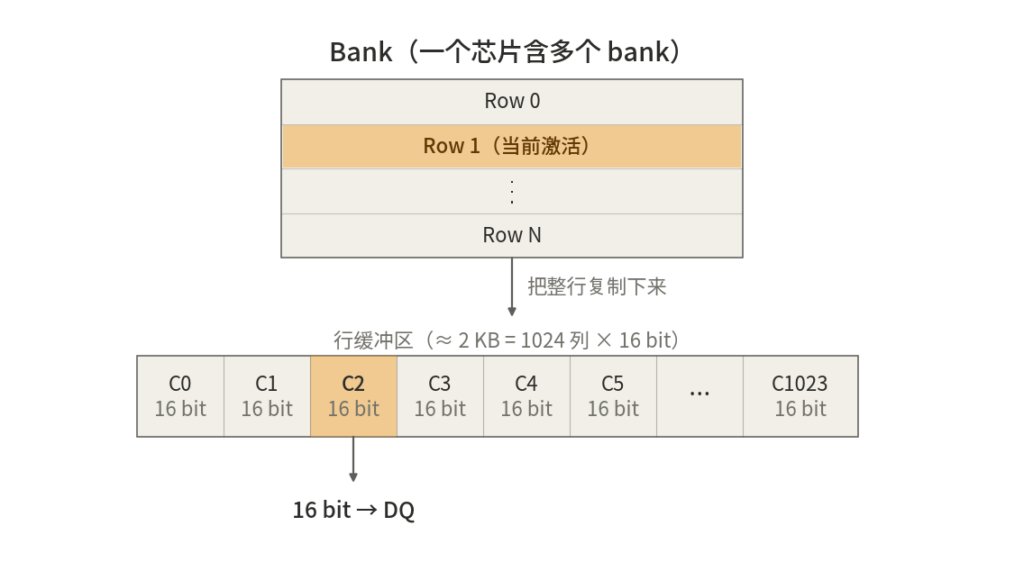
行缓冲区是硬件的缓冲区,一般储存着一行的数据,当进行读取时会把当前bank的一整行存到行缓冲区里,行缓冲区的每一列是16bit,每一个芯片的行缓冲区为 ≈ 2 KB,之后再次去读会检查是否命中然后从那16个针脚吐16bit的数据。
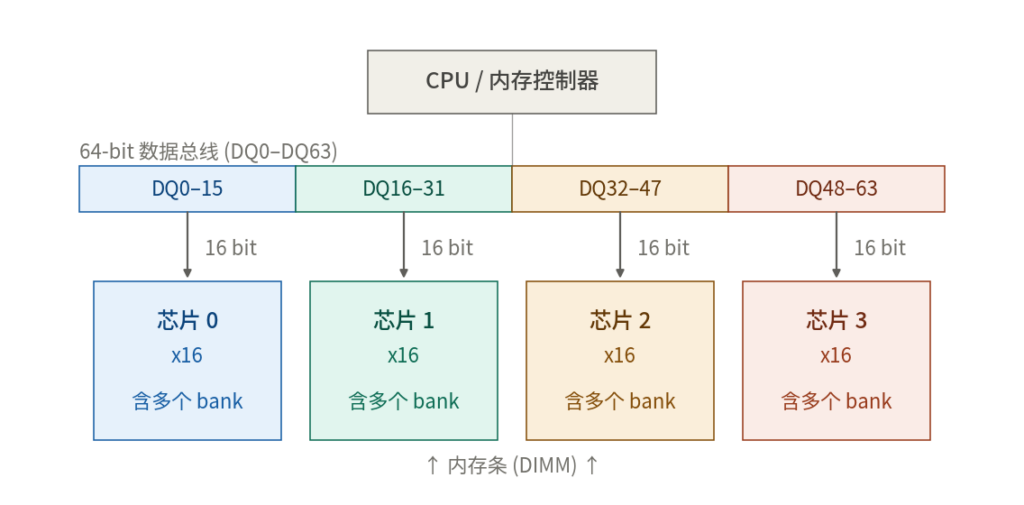
输入数据是怎么样的呢?硬件是焊死了64条DQ(Data I/O, Q是代表输出的意思)线,也就是总线传入了64bit的数据时,0~15bit到芯片0,16~31bit到芯片1这样,所以数据是均匀的分布的,如果想写入的不满64bit,64bit中凑数的就不管,通过DM(data mask)信号告诉对应的芯片跳过这些字节的写入,把需要写入的写到对应的芯片。
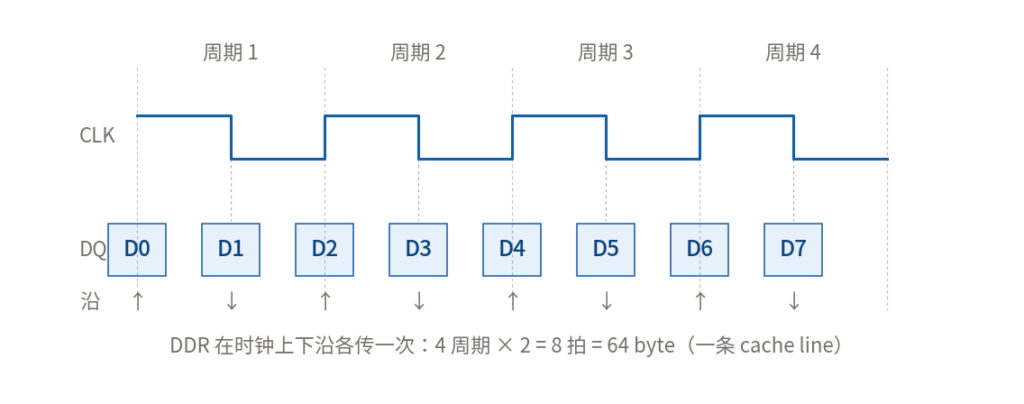
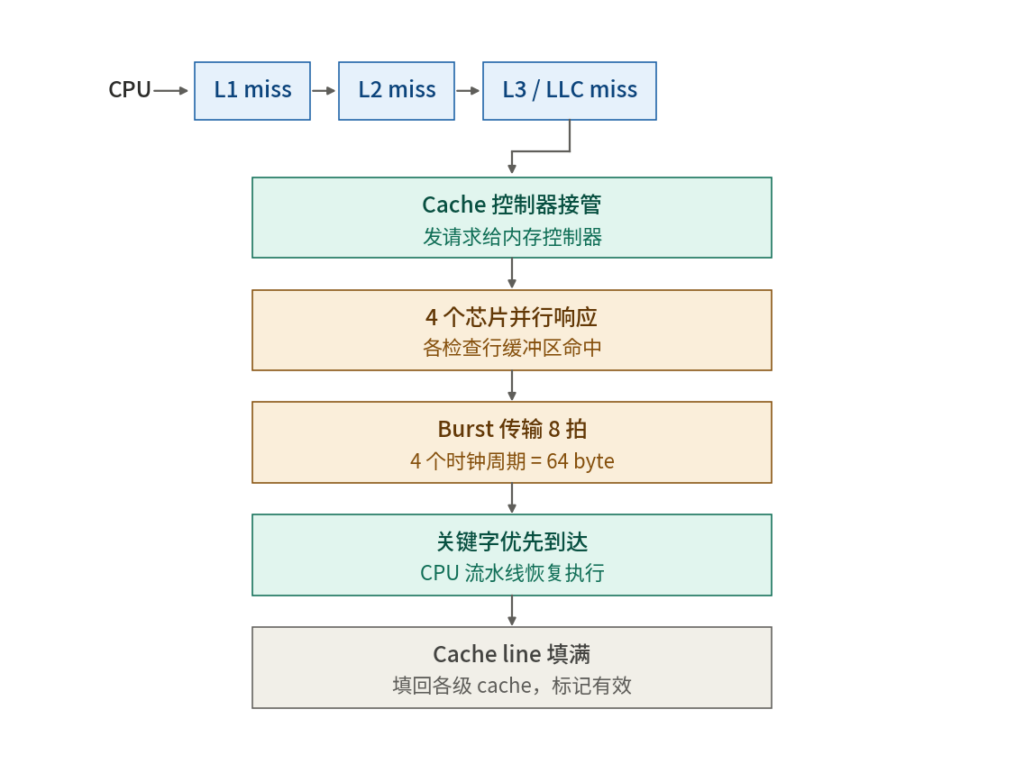
我们也知道CPU的缓冲区是64字节,但一次总线的读是64bit,那就需要读8次,当发生缓存miss时,缓存控制器(硬件)接管,发送请求给内存来获取数据,通过Burst模式让内存总线连续吐8次数据,每一拍吐一次,每一拍是什么时候?时钟信号每次变化如上升或者下降就是一拍,8拍吐8次,所以只需要4次时钟周期就吐完了,这样最终的数据总量能够一个缓冲区的大小。
同时在L1缓存中留一个地,如果满则根据规则如LRU等排出数据然后获得一块地,之后内存总线返回的数据会直接写入cache中,内存控制器会优先把 CPU 真正要的那个数据先吐出来,CPU在等待目标数据到时,流水线恢复继续执行,不会傻等到缓冲区被填满,在缓冲区的64字节填满后,标记该缓冲区有效。
整个流程就是这样:
cpu发现缓存未命中(miss),cache控制器(硬件)接管,发送请求给内存来获取数据,通过Burst模式让内存总线连续吐8次数据,每一拍吐一次,这样最终的数据总量能够一个缓冲区的大小,同时在L1缓存中留一个地,如果满则根据规则如LRU等排出数据然后获得一块地,之后内存总线返回的数据会直接写入cache中,内存控制器会优先把 CPU 真正要的那个数据先吐出来,内存总线一次返回64bit,每一个芯片返回16bit,每一个芯片通过检查该内存数据是否在行缓冲区,若在直接返回,若不在访问目标地址将该bank行替换行缓冲区,然后返回,CPU在等待目标数据到时,流水线恢复继续执行,若不满缓冲区64字节,内存总线继续随着拍子吐数据然后写入缓冲区直到凑够,缓冲区由硬件控制因此不需要发送中断让cpu来处理缓冲区数据。
以上讨论的读取流程都是在单个通道内发生的。
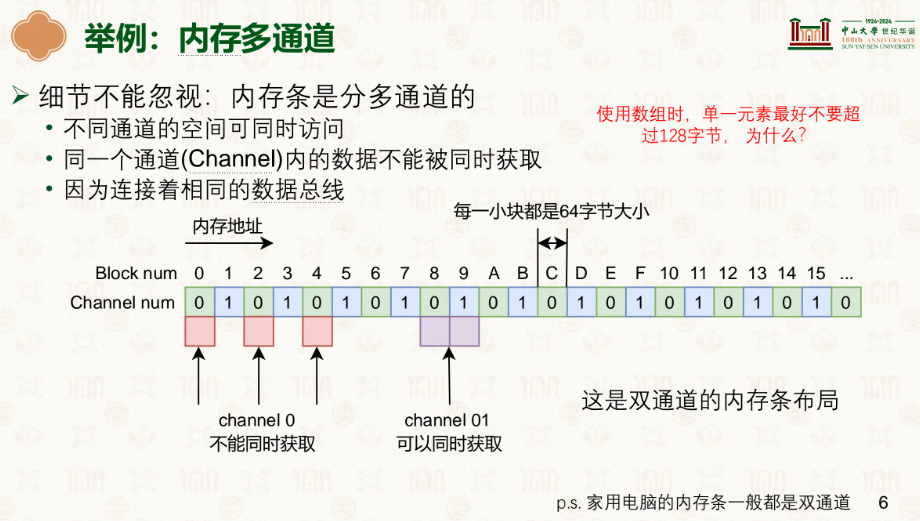
实际上,家用电脑的内存一般是双通道的,内存地址按 64 字节(一个缓存行)为单位交错分配到两个 Channel:Block 0 → Channel 0,Block 1 → Channel 1,Block 2 → Channel 0……
当 CPU 同时需要的数据分别落在不同 Channel 时(如 Block 0 和 Block 1),两个 Channel 各有独立的数据总线,可以完全并行地读取,效率翻倍。
但如果两次请求落在同一个 Channel(如 Block 0 和 Block 2),由于它们共享同一条数据总线,数据传输就必须排队,等上一次结束再进行,为什么也很容易推导,一次miss,Burst模式让内存总线连续吐8次凑够Block,在此期间你也没法让它顺便把别的吐出来。
了解完了硬件,我们再来看软件层面。
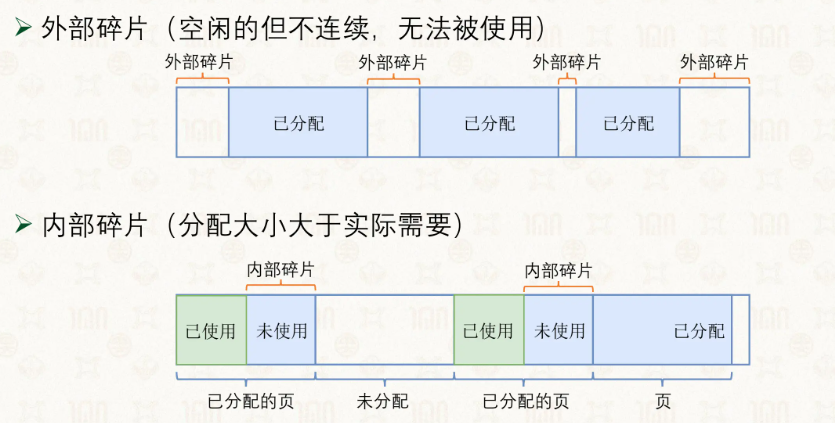
在实际的使用中,我们或多或少会遇到碎片问题,也就是内存利用不充分,碎片也分为外部碎片和内部碎片:
为此,我们设计了伙伴系统(Buddy System)和slab系统。
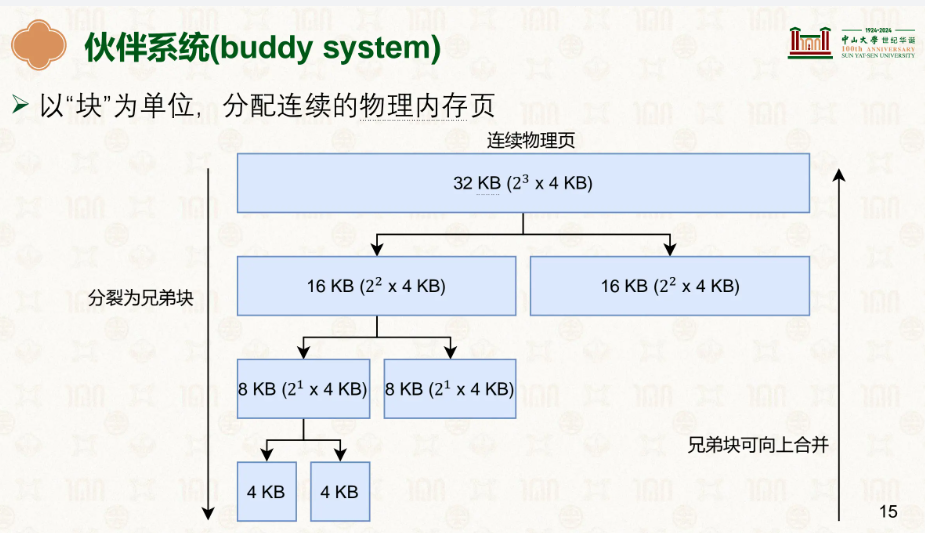
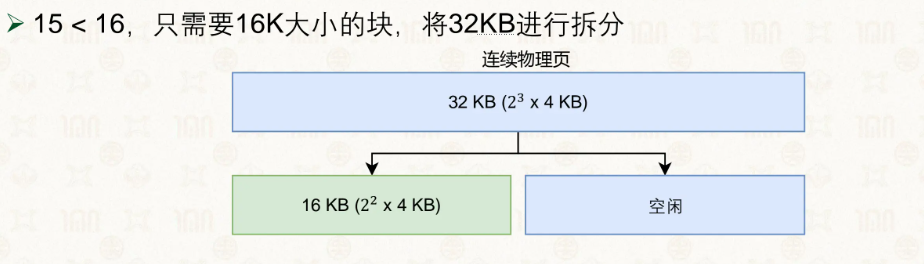
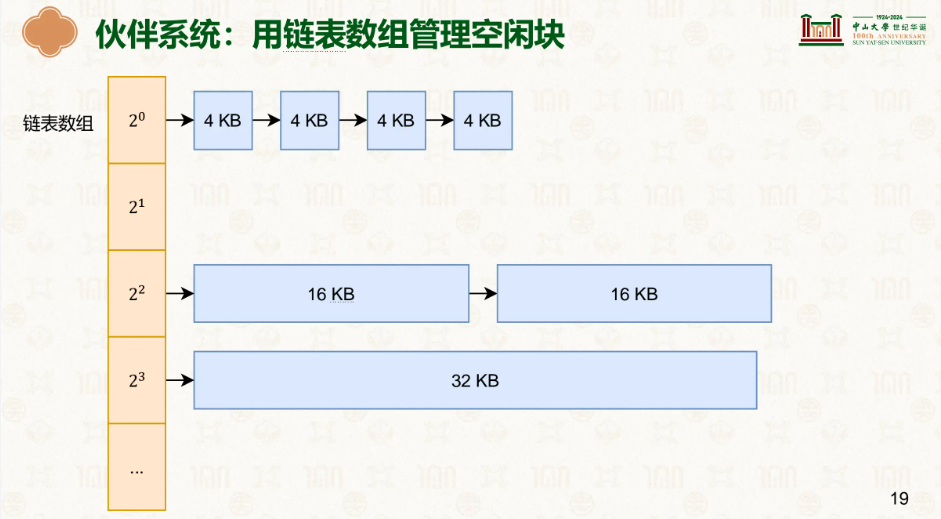
伙伴系统(Buddy System) 以页为单位分配物理内存,分配大小为 2 的次方页(1、2、4、8……最大 1024 页 = 4MB)。之所以限定为 2 的次方,是因为可以通过对页帧号做一次异或运算,O(1) 定位到它的伙伴块。

当一个块被释放时,系统会用异或找到它的伙伴。如果伙伴也空闲,就合并成更大的块,然后继续向上查找更大的伙伴,直到伙伴不空闲或已达最大阶为止,最终将合并后的块挂到对应大小的空闲链表上。分配时则反过来:先在目标大小的链表中查找,如果没有空闲块,就从更大一阶的链表中取一块拆成两半——一半分配出去,另一半挂到小一阶的链表上。通过这种释放时合并、分配时拆分的机制,伙伴系统解决的是外部碎片问题。

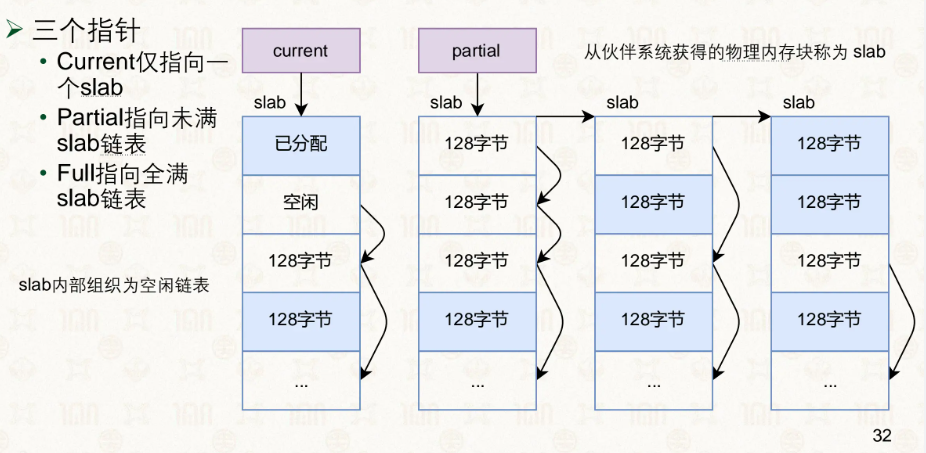
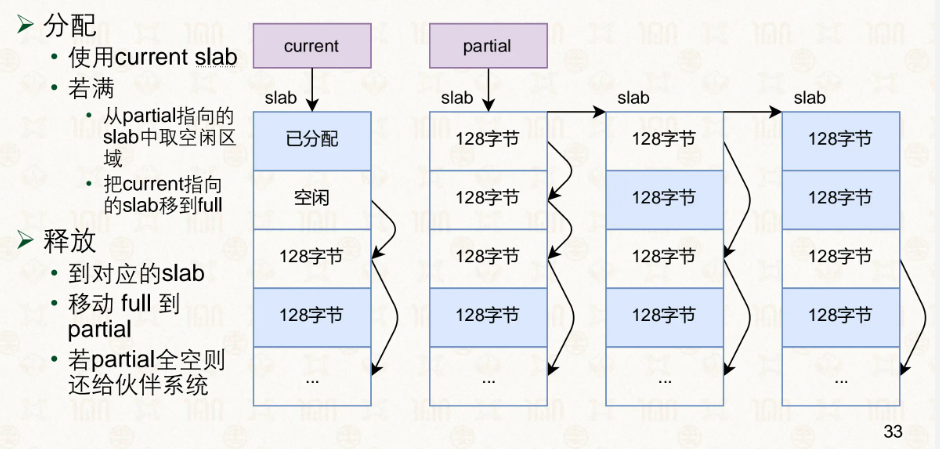
Slab 系统建立在伙伴系统之上,解决的是内部碎片问题。它先从伙伴系统申请整页,页一旦交给 Slab,就不再属于伙伴系统。Slab 将页切分成大小相等的 slot(几字节到几 KB),程序按 slot 为单位申请和释放。Slab 内部维护三条链表:Partial(部分使用)、Full(全满)、Empty(全空)。分配时优先从 Partial 链表中寻找有空余 slot 的 slab——如果每次都拿全新空白页,已有的 slab 里零散的空 slot 就永远用不上,那解决内部碎片的初衷就落空了。只有 Partial 为空时才去 Empty 拿,Empty 也没有才向伙伴系统申请新页。
从 C++ 标准容器中可以看到这两种思路的影子:vector 要求内存连续,扩容时需要分配更大的连续空间,类似伙伴系统提供连续页的思路;deque 由多个固定大小的块组成,块之间不要求连续,只需要有可用空间即可,类似 Slab 按 slot 分配的思路。
用户态的 vector/deque 并不直接接触伙伴系统或 slab。它们通过调用malloc,分配器在自己维护的堆里切出空间返回;只有堆不够用时通过向内核要更多内存,最终落到伙伴系统。
slab 是内核自己分配小对象时用的,用户进程不会走这条路径。所以这里说的是设计思路上的呼应,vector 像伙伴系统的”一整块连续大内存”,deque 像 slab 的”切成等大块按需挂”,并不是说底层真的分别调到了它们。
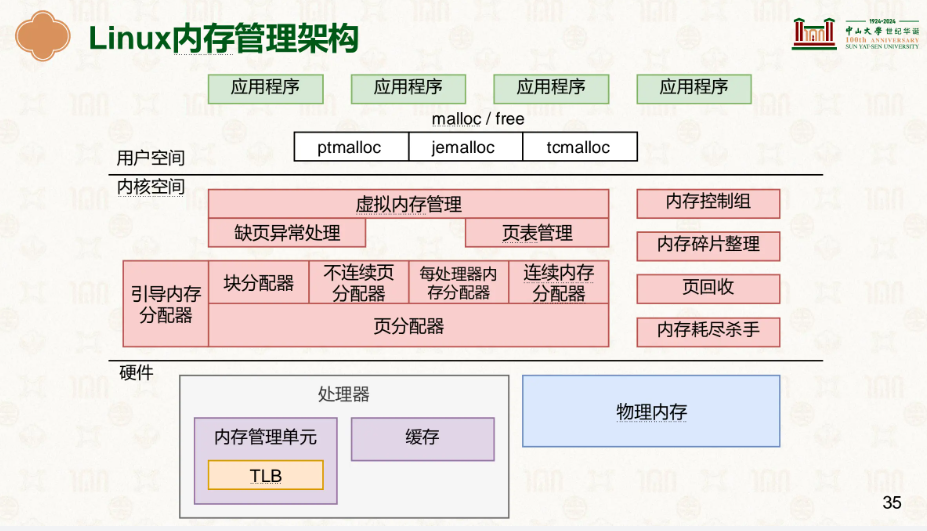
目前Linux内存管理架构:
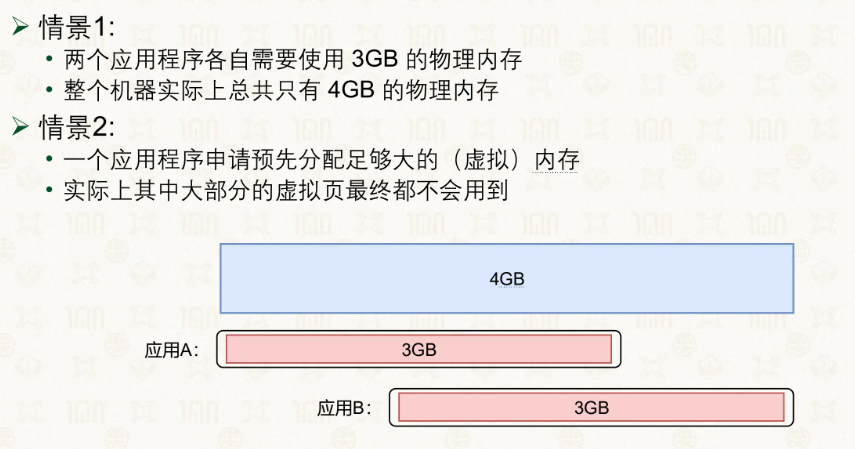
讲完了伙伴系统和slab系统,接下来就是换页,这是一种很常见的省内存方法,简单来讲,就是将内存中长时间不用的页放到磁盘中来节省内存空间,若是换到磁盘的页被访问,会触发缺页异常,然后将其从磁盘中换回来。
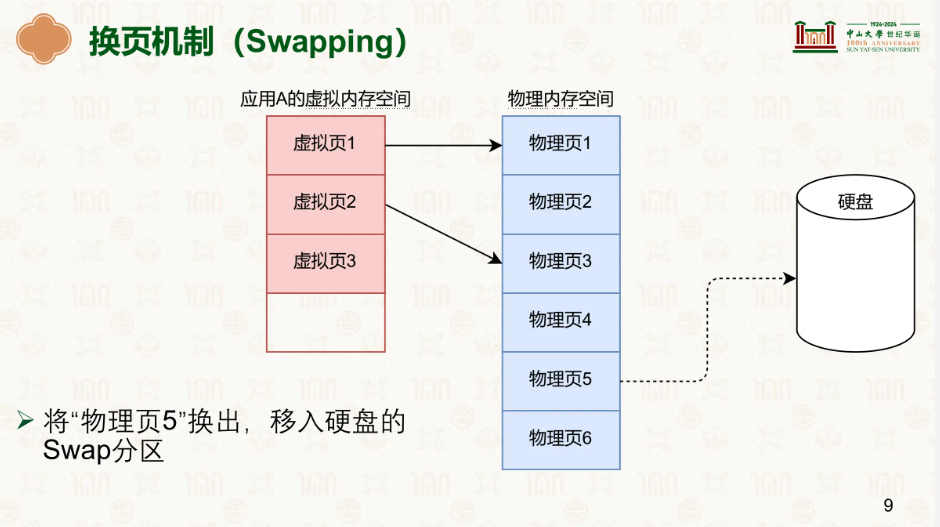
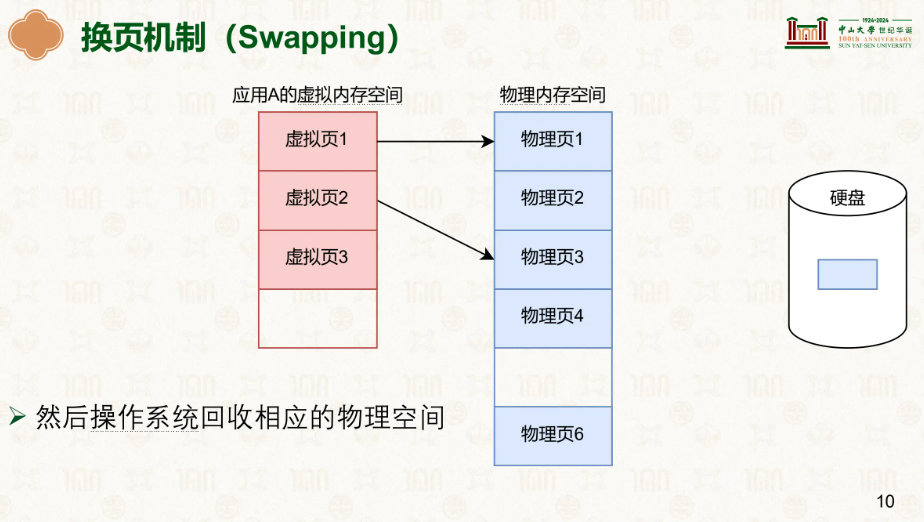
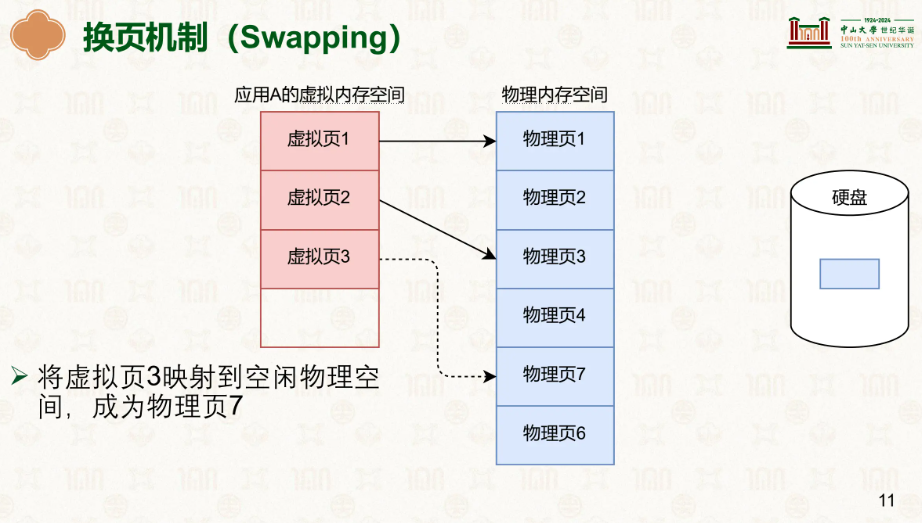
在这里我们能发现原来该页的物理地址被其他的用了,此时该页对应的页表项其有效位被置为0,代表无效,当虚拟地址一页页走到最后一级页表项时,会根据页表上的PTE值判断该页表项是否有效,如果无效就会触发缺页异常,PTE 在 present=0 时还会编码 swap 位置,OS 据此知道去哪儿找该页。
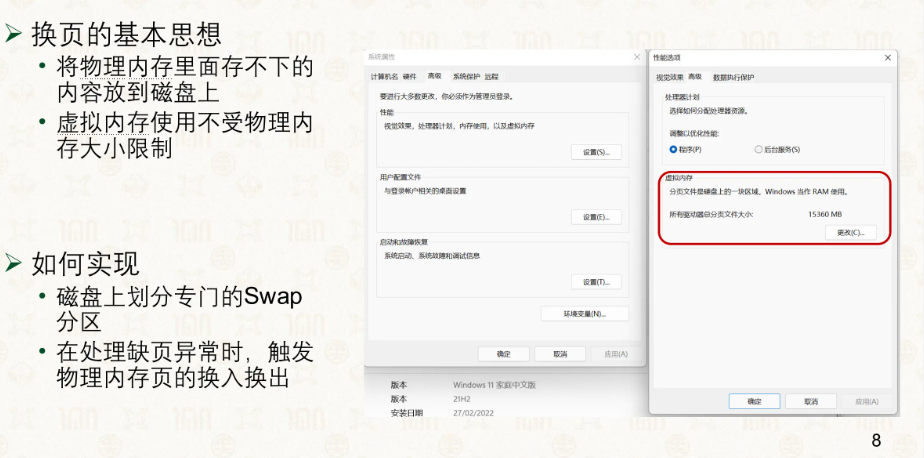
在 Linux 中,我们通常会配置一块 Swap 空间(可以是独立分区或文件)。当物理内存不足时,内核将不活跃的页写入 Swap 空间来腾出物理页。Swap 空间的大小决定了系统能把多少内存数据”暂存”到磁盘上。
而怎么换页,又是个很大的学问了…
接下来我们假设最多只能存3个页,多了就要弹出页来空出余量。
我们换页的原则是MIN原则:

但是…我们并没有这种上帝视角来看后面那里会用到哪里不会,所以这就是追求的最优情况。
接下来是几个策略:

先进先出策略,最先访问到的最先出去,这里先历遍到3,3压入,再2,压入,再3,已经在队列里了不管跳过,然后1压入,再遇到4,最先遇到的是3,就把3弹出去留出空间。
在上面我们就能发现一个很怪的问题,我们第二次遇到了3,但因为在队列里我们就不管,但多次遇到同一个页不就代表这个页可能在被较高频率的使用嘛,于是有了改进版:
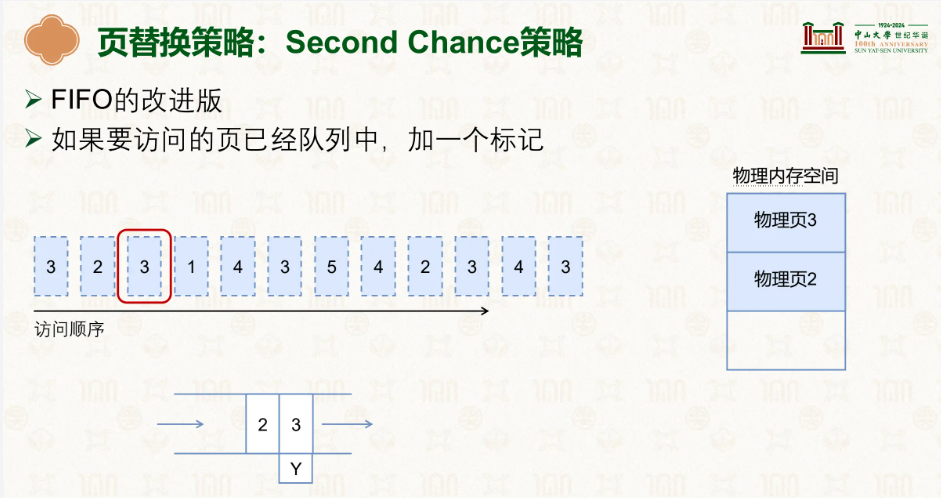
顾名思义,后面我们再次遇到了3,我们就给他个标记,等到4满了后,原本会弹出3的,但看它身上有个标记,就再给它一次机会,把3弹出然后再放到最后去,这下最头头的就是2了:
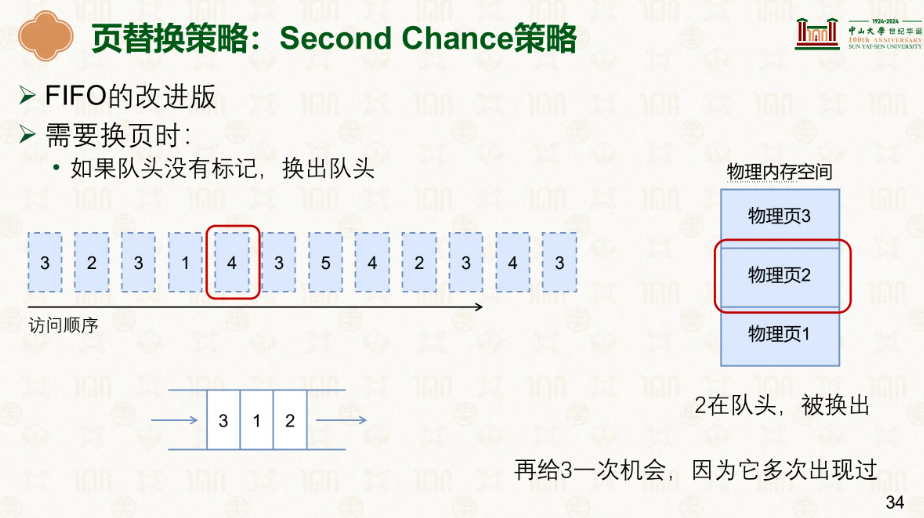
然后2就会死翘翘被弹出换页到磁盘。
它的工程实现叫 Clock 算法,把链表做成环形,用一根指针扫,遇到访问位=1 就清零放过,遇到=0 就驱逐。这是实际操作系统用得最多的算法之一,因为真正的 LRU 每次访问都要动链表,开销太大。
已经是老熟人LRU:

每一次遇到的都会更新,等满了还要加页是,就找最久没用过的弹出。
打个比方,假设是一个链表,每一次遇到,遇到是在链表里,就把节点弹出然后塞到链表的最前面,如果不在就直接加到链表的最前面,最前面的越新,等满了需要换页时,就跑到最后把最久没用的扔出去即可。

MFU听起来反直觉,但在某些场景下(如大量数据只扫描一遍),高频页可能已经用完了,反而是低频页即将被用到。这是非常特殊的策略,一般不常用。
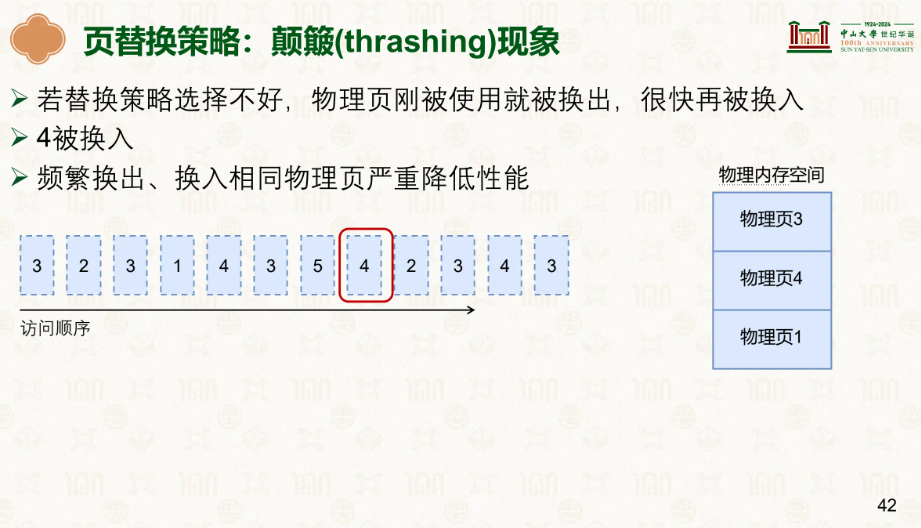
颠簸也很形象,刚换出去就加载回来,拖慢效率。

为了减少颠簸,我们弄了工作集模型:

简单来讲,我们依靠硬件来记录物理页的使用情况,如果该页被用了,访问位自己就变成1了,然后再设定一个阈值,超出阈值的部分我们就认为他不重要了。
假设我们t1的时候扫描了一次,如果访问位为1,就说明上一次扫描到这一次有被使用,那么将该页的上次使用时间设为t1,然后访问位设置为0,然后第二次t2的时候扫描,如果访问位为1,继续重复将上次使用时间设为t2,访问位设为0。
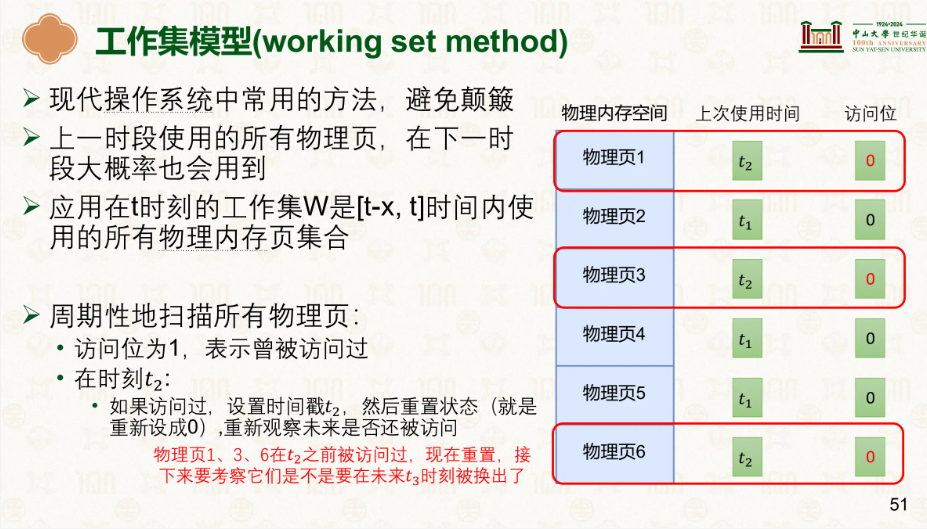
然后检查那些访问位为0的物理页,假设该页上次使用时间为t0,检查t2 – t0的时间差是多少,如果超过了阈值,就说明这个页我们觉得有点太老了,就把它换出去来节省空间。
你可能会想工作集和LRU有啥关系,工作集是宏观的看哪些页大概率不用了,然后保留可能会用到的,LRU就更细一点的看哪些页用的比较频繁哪些比较久远,二者是结合着用的而不是对立的。









