
在早期,程序直接使用物理地址,操作系统采用连续分配的方式管理内存——程序需要多少内存,就在物理内存中找一块连续的空闲区域分配给它。

如图所示,应用 A 被分配了两块不连续的区域,而应用 B 恰好夹在中间。程序直接操作物理地址,应用A能看到自己两段内存区域的起始地址和结尾地址,就能猜出中间夹了个别的应用,由于地址空间之间没有任何硬件层面的隔离,若应用 A 不是个好人,就会悄咪咪的进行数组越界,就能顺着自己的内存区域”溢出”到应用 B 的地址范围,直接读写应用 B 的数据。
这就暴露了一个严重的问题:内存没有保护机制,程序之间的边界形同虚设。
于是,我们引入了虚拟内存,在虚拟内存中,所有程序都认为自己独占内存,同时在他们眼里起始地址都一样,因此安全性也提高了。
而虚拟地址到物理地址的转换,就是耳熟能详的MMU了,CPU只知道自己的虚拟地址,然后走MMU得到物理地址然后访存。
早期的虚拟地址按照分段来,类似物理地址的分段。
虚拟地址的储存方式按照段号+段内偏移大小的形式。
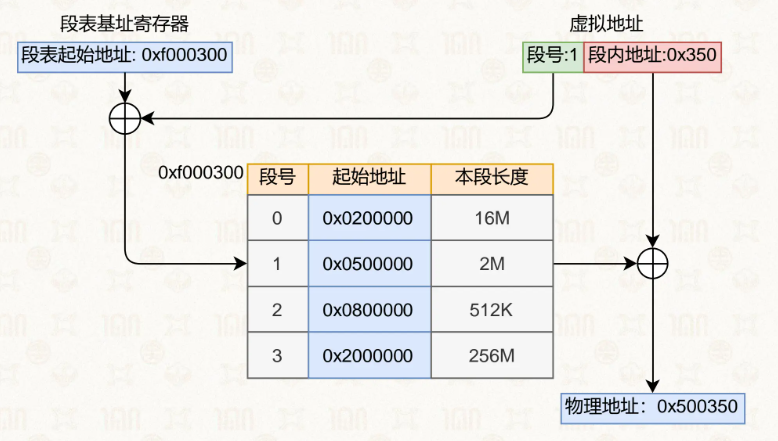
通过某个寄存器获取段表的起始地址,然后根据段号找到物理地址,然后加上偏移就是了,但问题也很明显。
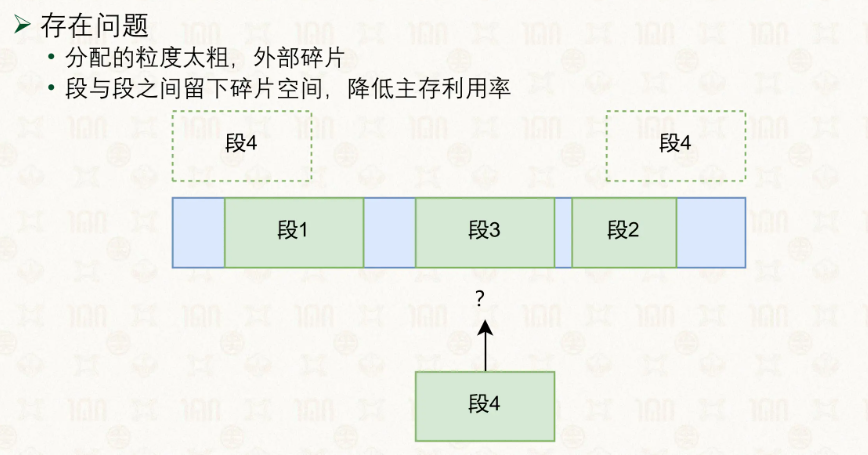
利用率不太行,也就是外部碎片过多。
接下来是现在最常见的分页形式,该形式将内存按照一页页的形式分好了。
虚拟地址的形式按照页号+偏移的形式。
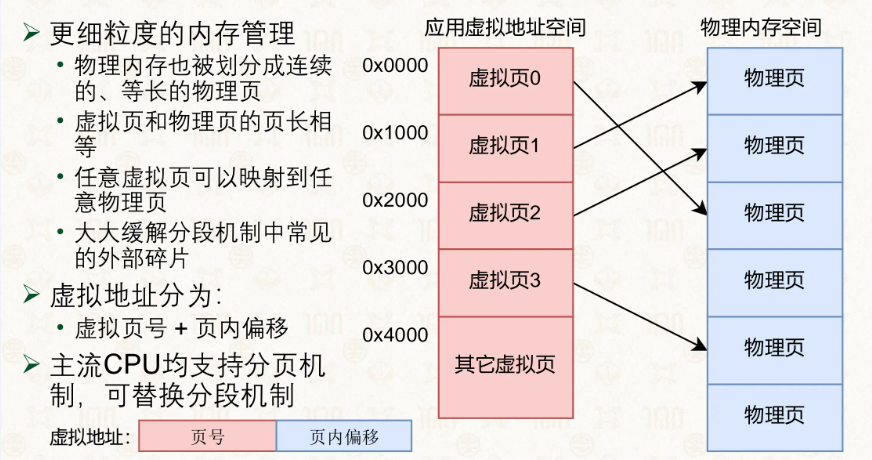
由此可见,虚拟地址到物理地址最重要的就是页号,因为偏移量总不能当作寻址的途径吧。
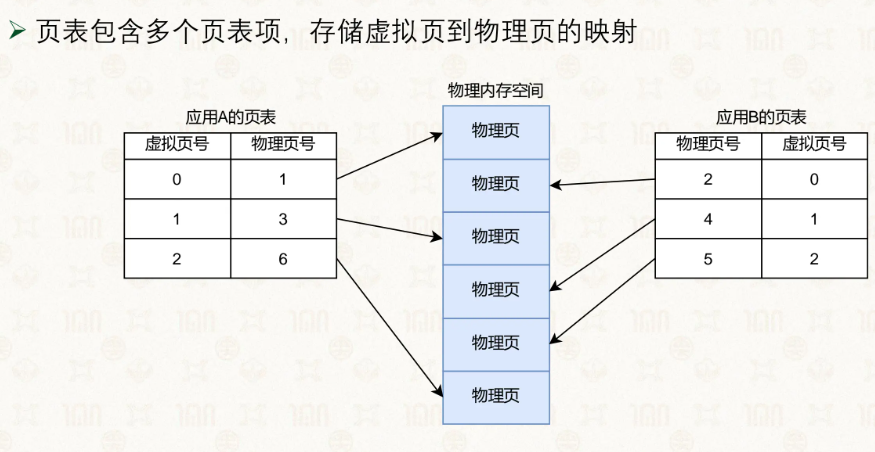
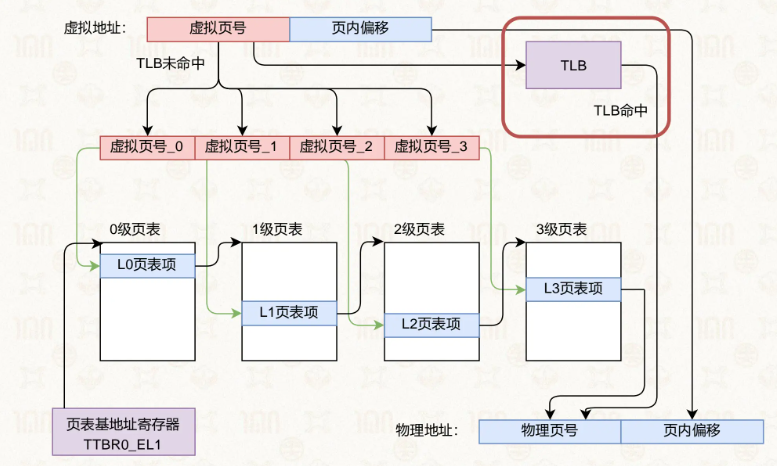
过程类似分段形式的查表,通过寄存器获取表的基址,根据页号找到对应的页表项。
在32位系统中,总的数据量是2的32此法,一个页通常为4k,也就是2的12次方,此时只需要2的20次方个页表项指向对应的页表,32位下一个页表项指针为4字节,也就是2的2的23次方字节:

而64位地址…情况就大为不同了:

存不下,根本存不下,如果老老实实把所有的页表项都写下来,电脑塞不塞的下都是个问题。
在计算机中有个很出名的话,时间换空间和空间换时间,开这里,我们就需要通过牺牲时间来换取空间。
(以下的思考暂时忽略实际,假设可用的内存范围为2的64次方)
我们思索一下,若是最开始就把所有的指针记录下来,很显然,内存不是时时刻刻都处于用满的状态,我们按需放指针即可,也就是每多一个页表需要指针对应时,才加入一个指针,而不是在其未使用时也有个指针指向它。
在实际的使用中,2的64次方过大,程序使用2的48次方的空间就绰绰有余了,因此虚拟页号+偏移总占据的位数为48位。
我们思索下页内偏移是多少,一个页时4k,2的12次方,页内偏移位0~4k – 1,所以页内偏移所占的位数为12位,因此虚拟页号共占36位。
一个页是4k,一个指针为8字节,那么每一个页的偏移范围为0~512 – 1,对应到2的9次方,很明显,这里可以分出9个虚拟页表,那么就可以分为4级页表:

同样是通过寄存器获得页的基址,在第3级获得物理页号后加上页内偏移即可。
在0~2级,因为页表项需要储存着下一个页表基址的指针,该页表项的64位全被用上了,但是,在3级页表中,页表项只有48位储存着物理页号,其余的位我们就能用来装上一些自定义的状态来利用起来:
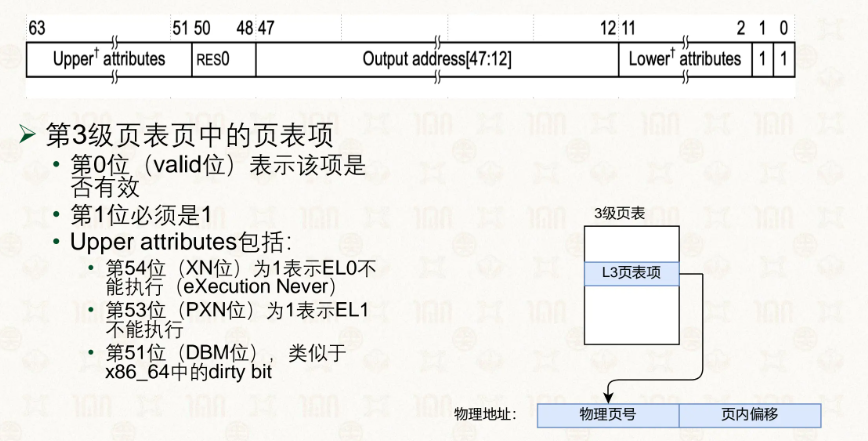
但我们还是会觉得太慢了,4级页表一个个查过去查到天荒地老,那么有没有什么加速的方法呢?有的有的,TLB缓存。
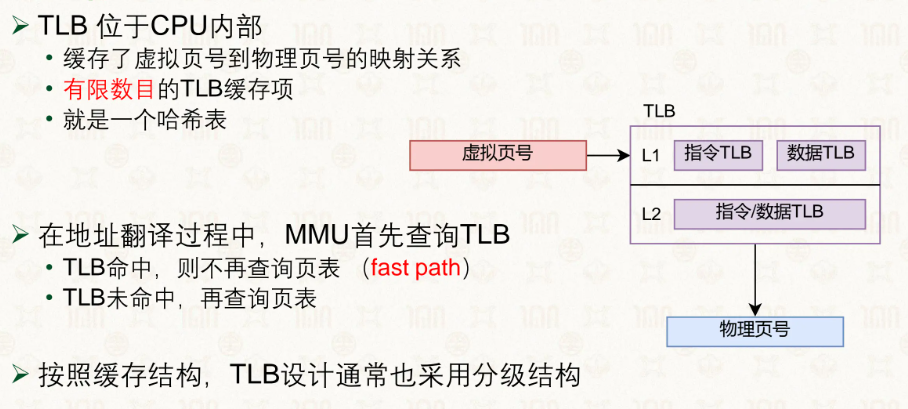
TLB刷新发生在页表的切换,每一个进程有着自己的页表,如果TLB在切换的时候不发生刷新就会出问题如:
程序A访存然后TLB中储存了对应的缓存,虚拟地址A对应物理X,然后程序B访存然后TLB缓存,就可能出现数值相同的虚拟地址B对应物理Y,因此,我们需要加入识别程序的功能,避免不同的程序相同的虚拟地址导致错误。

但是,每一个程序切换就要把TLB flush一遍也太费劲了,因此我们引入了标识码,给程序或者收页表打上标识,TLB通过判断缓存地址对应的ASID和请求程序的ASID来分辨是否是该程序的缓存地址。

在CPU最开始启动的时候,都是物理寻址,直到调整了下控制MMU开关寄存器开始虚拟->物理的形式,但这样就出现了一个问题,在内核态,我们需要小心翼翼地进行虚拟->物理的变化吗,在用户态是为了安全和隔离,那么在内核,我们只有操作系统这一个超级大用户,我们理论上是不需要让它继续遮蔽的,但是,如果单独设计让内核走物理,用户态走虚拟有会显得很割裂,因此,在开启MMU的情况下,操作系统也会走虚拟->物理,但是走的很敷衍。
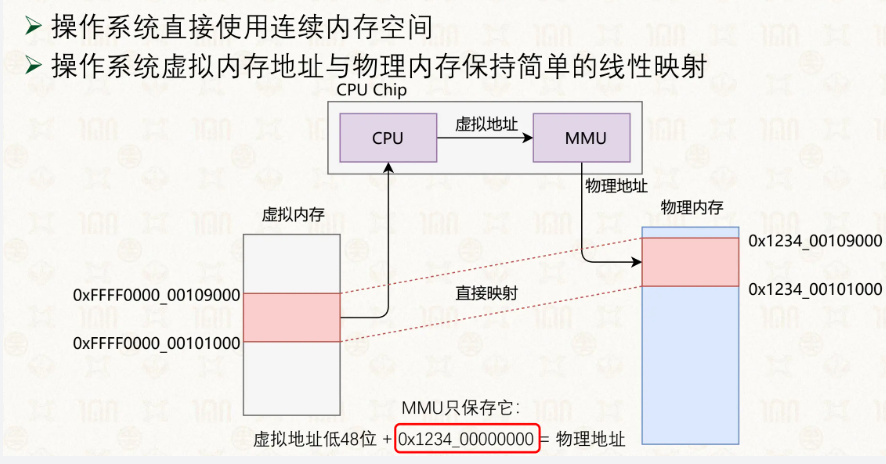
可以认为就是加了个物理地址加一个固定的值,然后走MMU就减掉就得到了所需的物理地址。
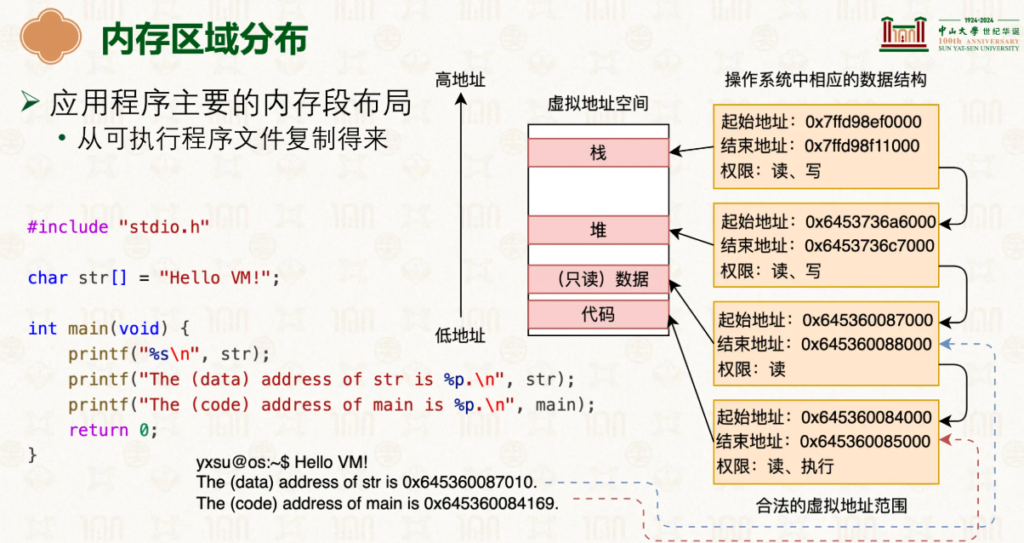
而一个虚拟地址的分布是怎么样的?在CSAPP中,我们了解了栈、堆、程序代码、动态链接库等:

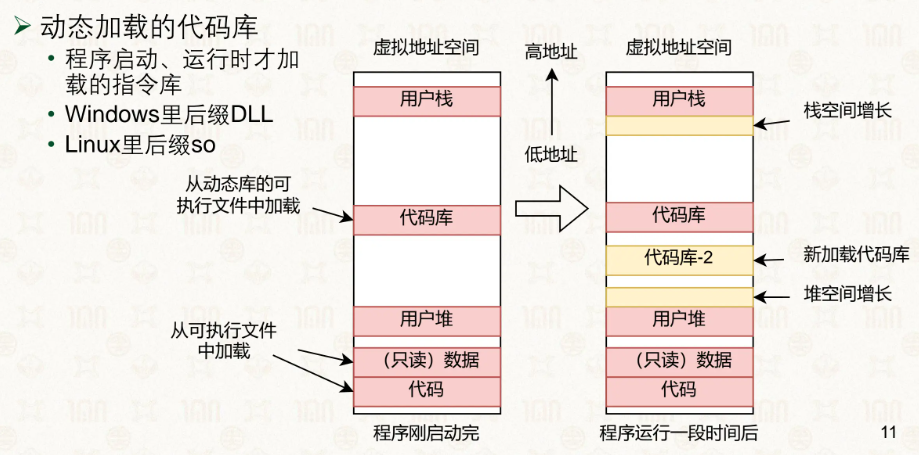
而一个程序刚开始运行时,虚拟地址的相关信息都是从哪里来的?ELF(可执行性文件)里来的。
ELF从源码到可执行性文件文件需要经历多个过程:预处理、编译、汇编和链接
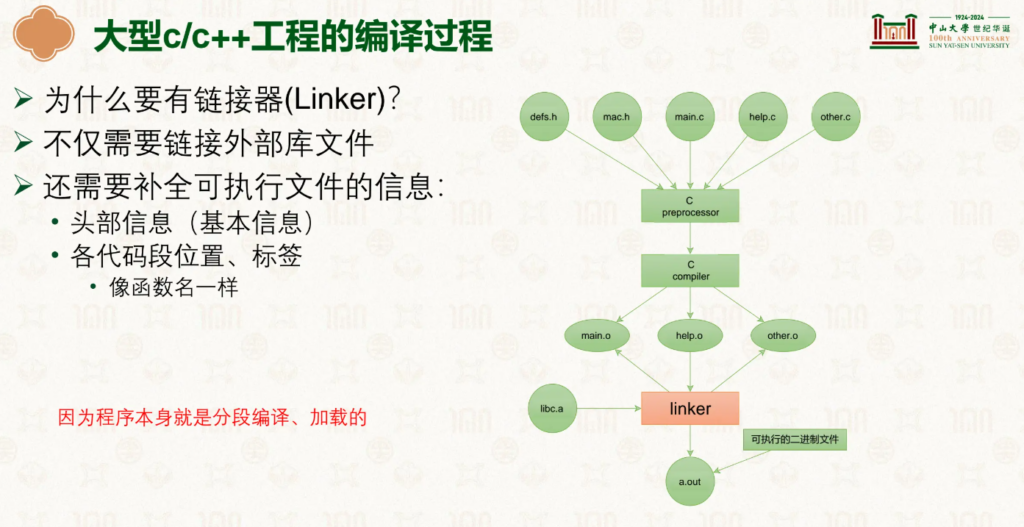
预处理展开include文件,然后程序通过编译生成汇编代码,在汇编阶段将汇编代码转为二进制代码,最后通过链接按需拿取二进制代码生成最后的程序。
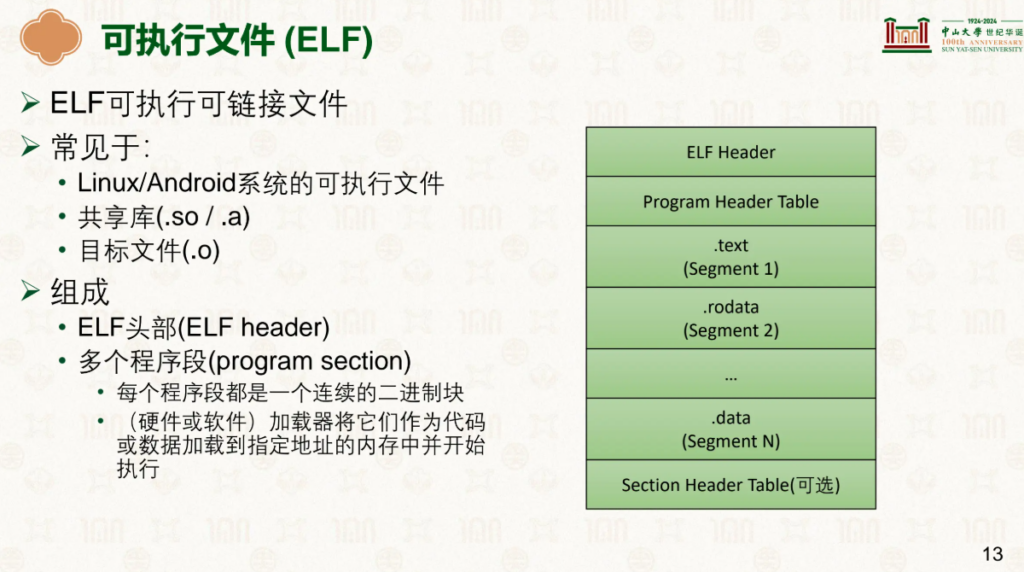
ELF中按照头部+多个程序段,程序段有.text、.rodata、.data、.bss等:

对于一个程序执行,我们需要先将程序加载到内存,然后再开始执行代码

有些时候,我们想把内容映射到内存上可以使用mmap,这样就能将内容当作是数组来历遍,就很方便:

当内容过大时,我们一般采用延迟映射,也就是用到了才加载到内存中。
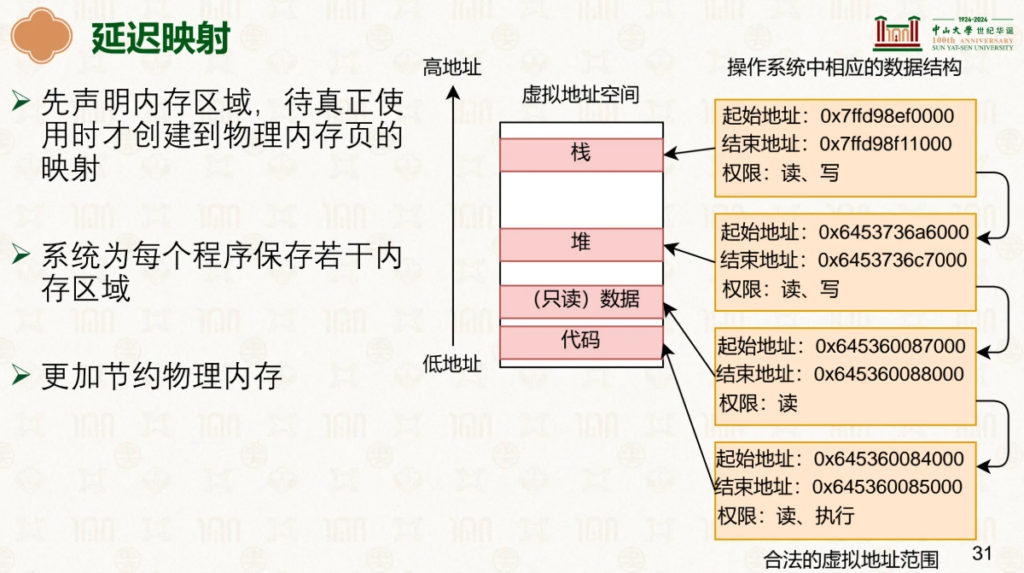
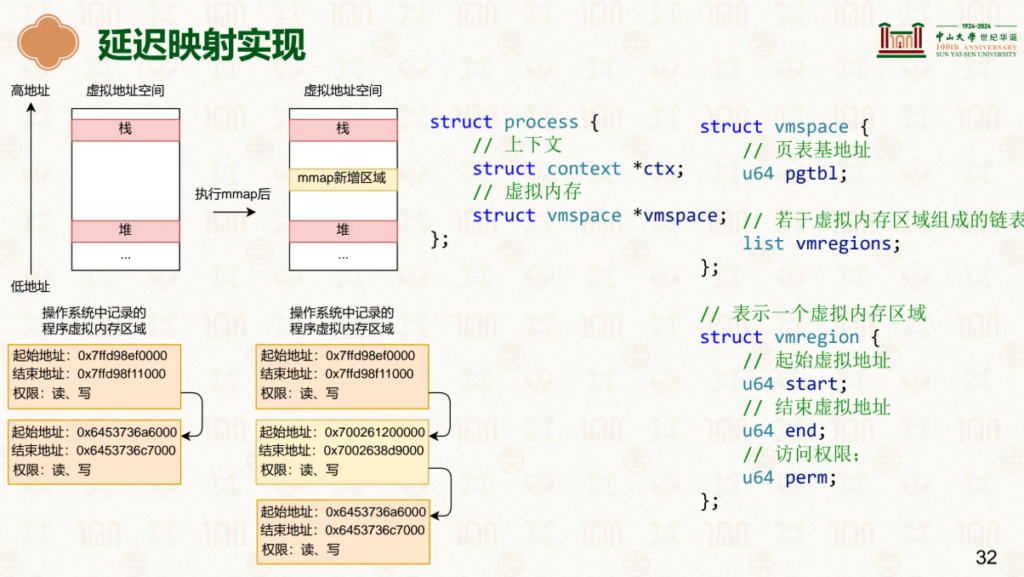
也就是当访问到一个未在虚拟页表中映射的地址时,会触发缺页异常检查,操作系统介入将虚拟地址映射到所需的物理地址。
关于缺页异常的实现我们日后介绍,现在太早了…

接下里我们进入性能提升部分~
在进程fork进程时,我们很容易发现二者会有大量重叠的部分,少部分会被进行修改但是大部分都是共用并且不动的,那么我们有没有什么可以优化的呢?
当然有,写诗拷贝(cow)
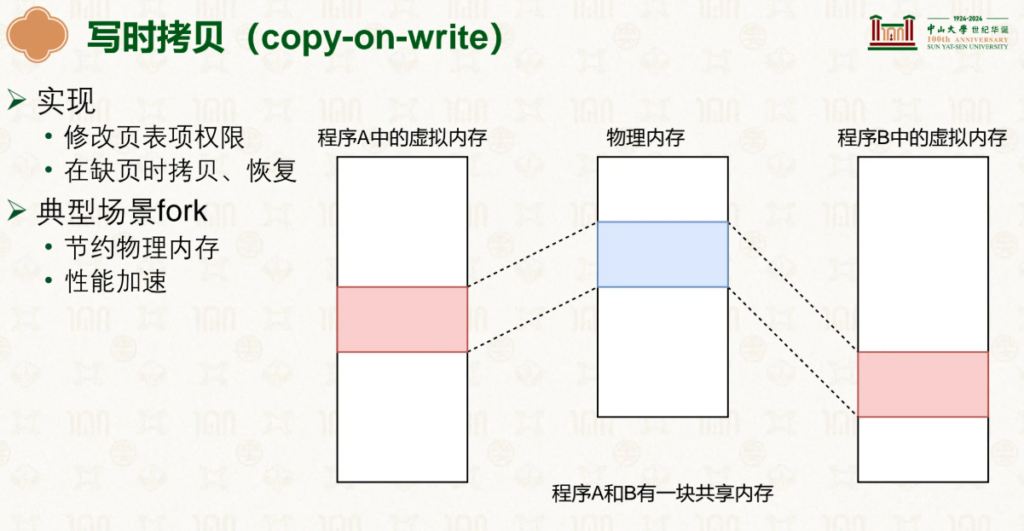
二者的虚拟地址共享一个物理地址,当发生修改时,程序检测到没有写的权限(还记得第3级页表空余位嘛),就会自己copy然后私有这个修改的部分:
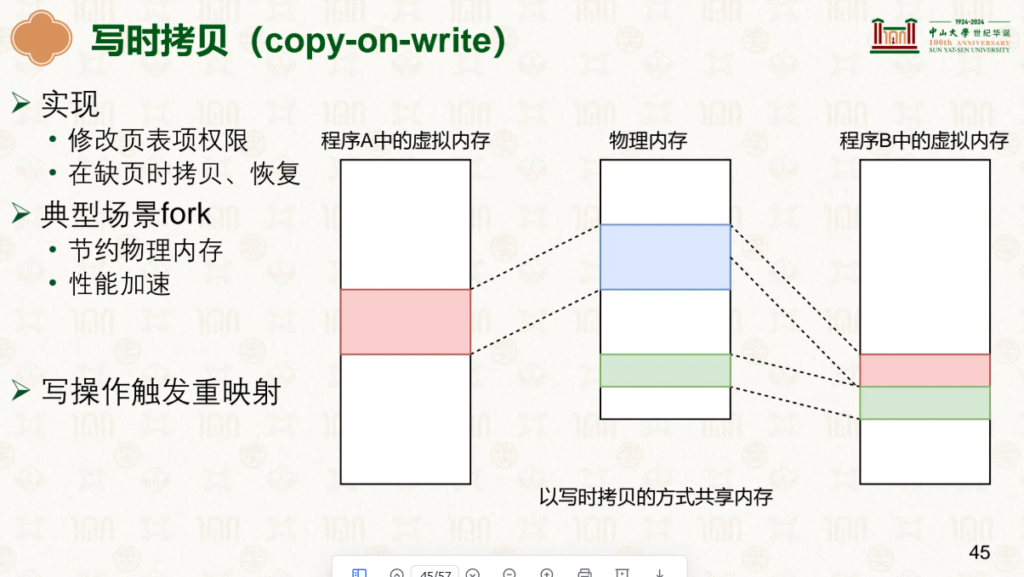
而内存去重就是基于此,我们秉持着既然数据相同那你们就共用呗,等你要修改再创建新的:

打开我们的任务管理进入内存,我们就能看到压缩部分,也就是去重部分:

有些时候,一些数组等很大,我们知道它占据4k的页话会占据很多个,而我们又要经常访问的话,就会大量的占据TLB的空间并且效率不一定能维持较高的水平,因此我们引入大页,大页是什么呢?我们是第3级页表储存着物理地址的页表,也就是指向一个4k页,那如果我们转换下思路,原本的第2级页表项指向的是第三级页表,那如果我让这指向的不是第三级页表而是一大块物理地址的开头呢?
那么这个物理地址会是多大?我们将第三级页表转化掉了,因此我们只需要第0、1、2级页表,也就是27位,那么偏移就能有21位的空间,2的21次方对应什么呢?4K * 512,2MB,因此这个一大块就是2MB,以此类推我们就能得到更大的大页能占多少空间。










