
当你的手机收到来电、访问网站时,你是否有好奇中间发生了什么。
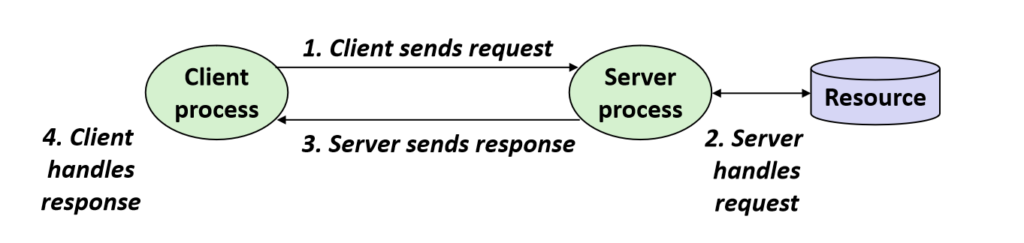
这是一个简单而朴素的阐述,客户端向服务器发送请求,而服务器接受请求并向客户端发送响应回去,然后客户端处理服务器发回来的响应,这就是一次简单的客户端到服务器的请求。
让我们继续向前而不是止步于此,更深入的探求发生了什么,在Unix中,一个出名的想法就是一切皆文件,它将硬件等都抽象为文件看待,客户端向服务器发出请求时,数据被分为多个数据包发送给服务器,而服务器接收这些数据包,我们可以把这些数据包看作文件中的内容,或许你可以把这个文件看成一个不断会出现信息的文件。
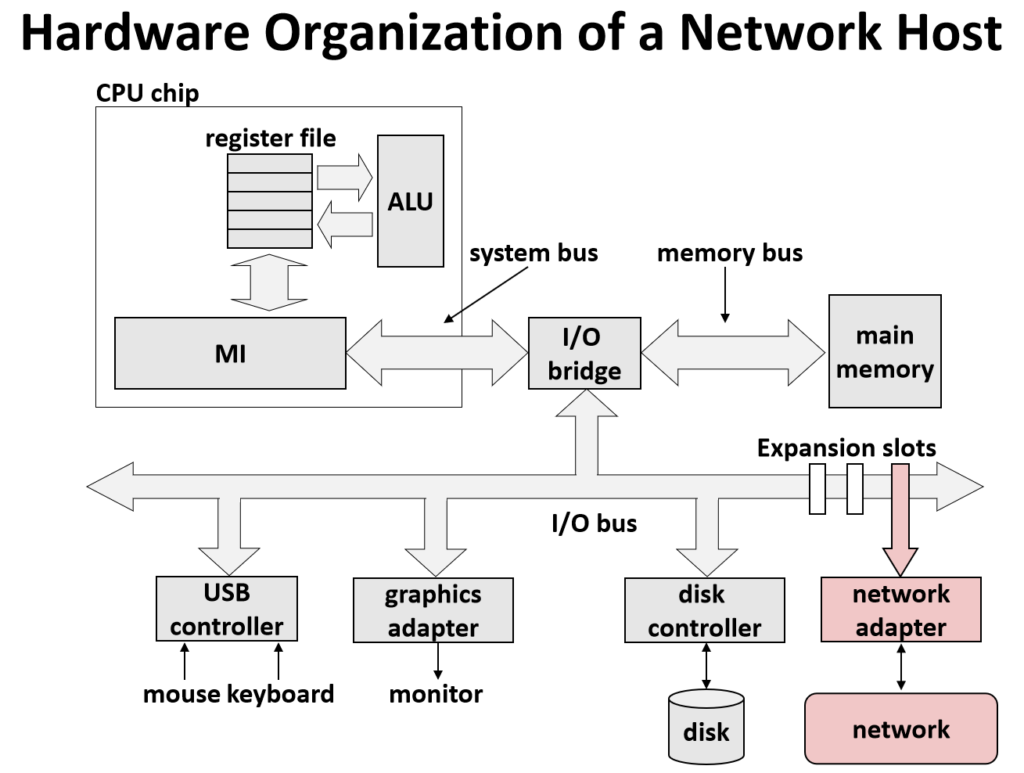
当谈论到网络,网络分为多种:
比如SAN (System Area Network),LAN (Local Area Network),WAN (Wide Area Network),
可以将SAN看作是数据中心的某个特别的网络,延迟低、速度快。
LAN就是局域网了,学校的内网、公司的内网等都能看作是LAN,由组织个人管理。
WAN,可以看成是将不同区域的LAN连通起来的中继网络。
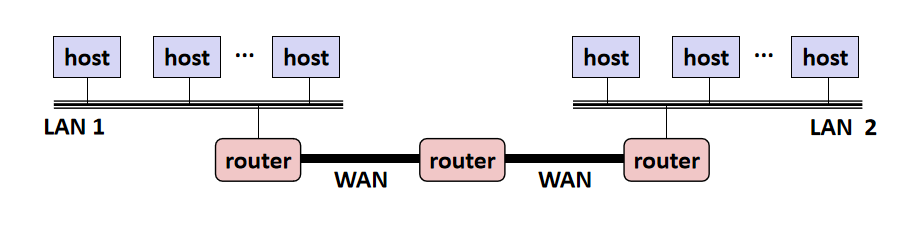
在早些年间,网络并不复杂,因此一个WAN就可以很好的解释为多个LAN间的连通,但随着发展,网络愈发的复杂,一些网络看不出其中的WAN是什么,就好比:LAN、LAN、LAN、LAN,左区域的LAN能和右区域的LAN连通,但并没有进行特别的中继网络。
因此我们引入一个新的概念,将多个网络连成的网络称为internetwork(小写的i)。
Internet(大写的I),就是常说的互联网,连通全世界的网络。
这时,我想你应该有了点粗糙的概念与网络,让我们接着往下看,当host(主机)需要向外发送信息时,可以通过hub(中继器)来传送。
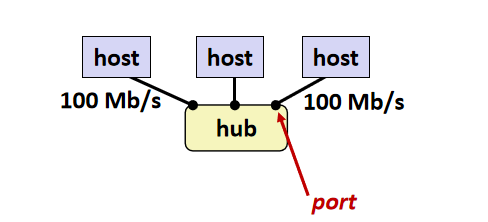
hub的作用是将信号沿着线路发送给所有相连的host,你可能会担心每台主机都给所有相连的发送信号,这会不会导致host的cpu疲于处理信号,这些信号都会被网卡先进行判断,但数据是需要的情况下才会使cpu运作,因此不必担心。
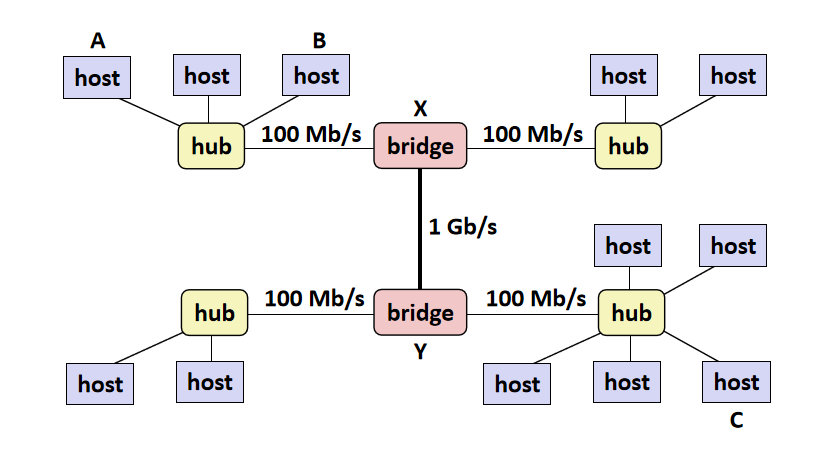
这就是一个简单的局域网(LAN)。
接下来让我们看看主机怎么通过LAN、WAN来进行连通:
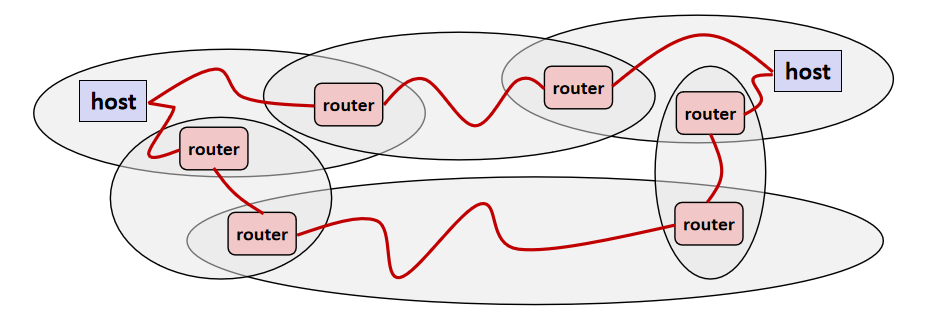
这里我们忽略一点严谨性,将只包含router的椭圆看作WAN,将包含host的椭圆看作LAN,怎样,是不是清晰多了。
这时候就引出了一个问题,我这里数据的处理跟你那里的数据处理一不一样呢?我这里的LAN传递都喜欢发数据[你好][数据],而你那里却是:[数据][再见],那如果我把我数据传你那里去,不就有问题了对吧,你按你的习惯来解数据,将[你好]也当作了数据不就出问题了对吧。
这时候就引入了协议(Protocol),通过协议来规范了行为,规范了数据的格式,让该协议下的数据到达他处,也能通过该协议来解出数据的意思,而不是会出错。
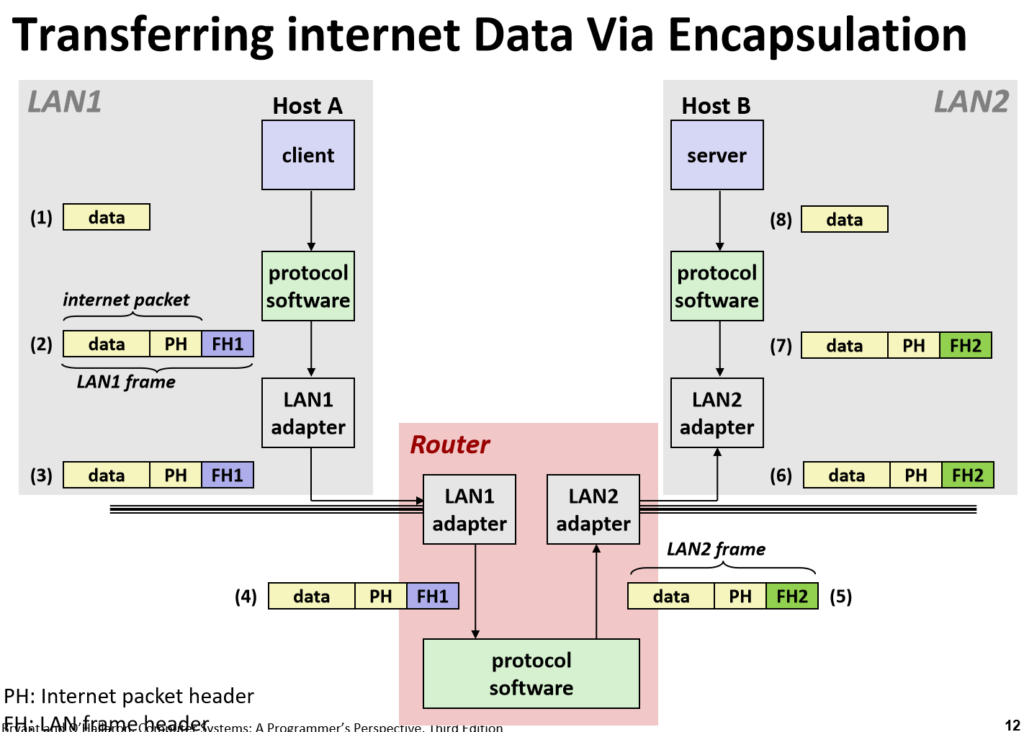
这里就是数据传递的过程了,data就是数据,PH不会变,它可以看作是目标的地址,比如某小区几幢几单元,FH是会变的,可以看作每一个阶段需要前往的位置。
我们把这个data当作快递,PH是快递单上的地址,而FH是当前需要前往的下一个地方,比如:刚打包好包裹,FH就是快递站,到了快递站后,FH就是分拣中心了。
协议在这里的哪个阶段呢?
我们先简单的讲一下协议的种类:IP、UDP、TCP。

我们将IP看作不可靠的,尽力而为的,因为它就相当于贴那个快递单,它就负责贴上去,上面有着快递的地址,快递员咋送,能不能送到它就不管了,就算数据中途损失、丢失,它也不会跟你再要一份。
UDP就是快递员,但它不检查它送的货物是否有损,货物有多少就直接放在门口就走了,不告诉收件人到了没有,也不会告诉寄件人是否送到。
TCP是富有责任心的快递员,因为快递发来的顺序是不一样的(数据包发送的速度不一样),它送到时会先检查货物送到的顺序对不对(比如到的顺序是包裹1、3、2,它会把1给出去,到了3时先不给,2到了再把2、3给出去),如果对了就先放给了然后再检查接下来的,若是有误就跟发件人再要一份,若是收件人确认无误还会回去告诉寄件人送成功了。
你是否好奇地址是什么,包裹上的快递上贴的是什么地址呢?
一个公网ip,也就是在Internet上独特的ip地址,该ip地址下可能是多台机器,也可能是一台。
这个地址会不会被用完呢?目前常见的是ipv4的ip,通常的形式为例如:128.0.0.1,每一个数字对应1字节,所以最大为255.255.255.255,ipv4 一共 32bit,总量约 42.9 亿个地址,但并不是全部都能自由分配使用,IPv4 可分配池在2011年就已耗尽,所以人们想了一个挺疯狂的想法,既然数字太小会用完,那我扩大数字规模,让它几乎用不完不就好了,ipv6出现了,它的数据量来到了128bit,这下根本用不完了,但目前主流的还是ipv4,ipv4和ipv6共存,ipv6的使用量在逐渐上升。
如果你想跟我一样搭个博客的话,那你就需要一个公网ip和一个网址,通过DNS解析让网址和ip连接起来,DNS是什么?你可以把它看作为一个巨大的数据库,DNS解析就是将网址和ip对应起来然后放进该数据库里,之后访问网址就是通过查询然后访问ip了。
你可以通过nslookup来查看网址对应的ip
ponsde@ser6401954687:~$ nslookup www.google.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: www.google.com
Address: 142.250.71.196
Name: www.google.com
Address: 2404:6800:4005:816::2004
好咯,目前简单的部分就到此位置,之后将会更加深入、从代码的角度看是如何实现的。
接下来让我们进入代码的层面。
先让我们总体看一下客户端和服务器之间沟通的过程,接下来让我们逐步讲解每一步。
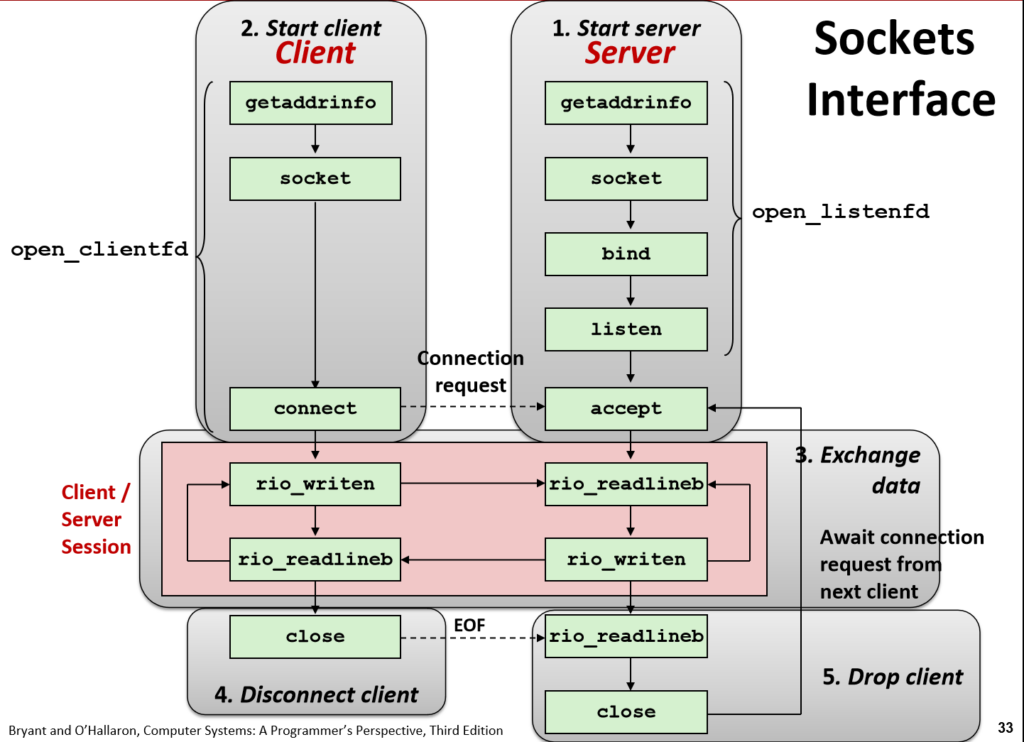
我将从服务器开始讲起:
让我们先介绍一个套接字(socket)。

我们可以将socket抽象为一个文件,该文件接收、发送通过网络的数据,可以看作是专门用于该方面的文件。
int socket(int domain, int type, int protocol);让我们来看一下这三个参数分别对应什么。
domain,对应地址的类型,比如ipv4。
type,socket的类型,也可以看作是它是负责接收哪种协议的数据,比如UDP和TCP。
protocol,具体协议号,一般填0,代表根据domain和type自动选协议号,也可以具体写IPPROTO_TCP 或者 IPPROTO_UDP。
这一步我们是通过 int fd = socket(int domain, int type, int protocol) 获得socket的对应的文件描述符,fd,这样就能通过fd来读取、写入socket文件。
(在客户端,socket的domain对应目标地址)
bind阶段,就像它的名字一样,将socket文件与服务器的某处绑定起来。
int bind(int fd, const struct sockaddr *addr, socklen_t len);fd就是通过socket得到的文件描述符,接下来的就是关键的参数了。

sockaddr的struct结构分为两块,sa_family和sa_data。
sa_family就是对应着该socket类型为ipv4、ipv6或者AF_UNIX(Unix Domain Socket(本机进程间通信))。
sa_data就是data,里面存放着数据,存放着什么数据呢?让我们接着往下看。
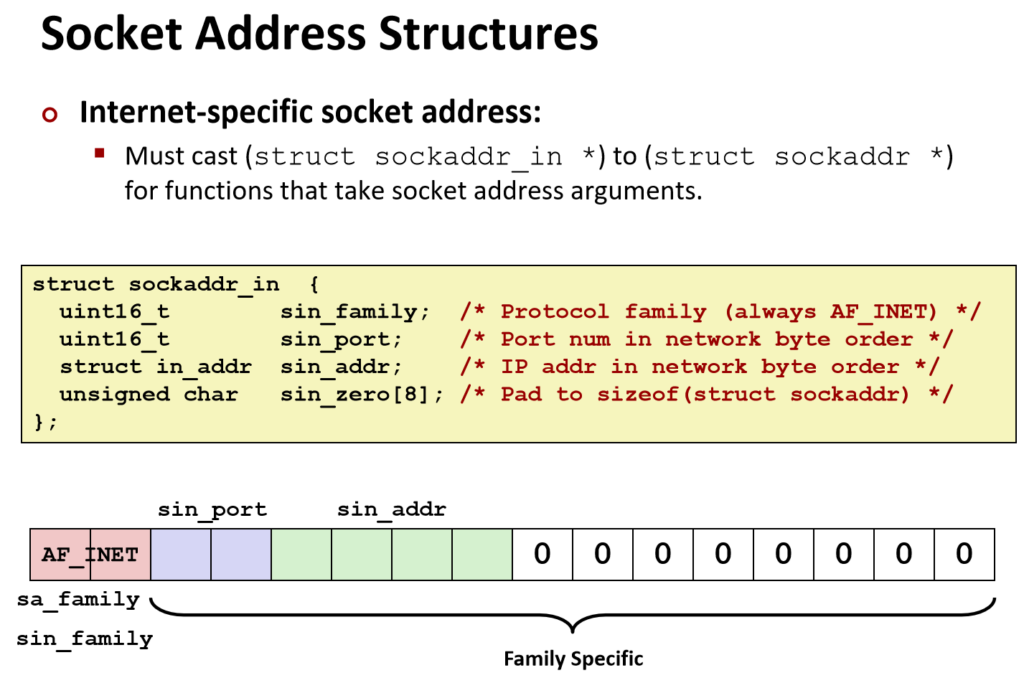
我们往函数里传递的其实是sockaddr转换后的sockaddr_in。
sockaddr_in里面存放着多个数据,你能发现一个似乎相同的数据,family,这对应着地址的类型,虽然前缀不一样但功能是相同的,那为什么要往函数里传递一个强制类型转化为sockaddr的sockaddr_in,而不是直接传递sockaddr_in呢?
在早些时候,c语言中并没有void*指针,而为了应对多种地址类型的处理,放弃了考虑bind_ipv4和bind_unix(当时还没有ipv6)这种方式,为了统一处理,就加入了sockaddr这强制类型转换,就如上面提到的,函数通过family来分开处理后续的数据,按照各自地址类型的处理方式处理data,因为它是data[14],所以转换前不同的数据类型就不会有影响,因为统一放入了data中。
讲完了为什么强制转化数据类型,让我们继续看接下来的3种数据:
sin_port,对应端口,在这里占据2字节,因此端口的范围是0~65535。
sin_addr,对应ip地址,比如设定127.0.0.1,端口为3000,bind成功的话,该地址的该端口就属于该fd了。
struct in_addr
{
uint32_t s_addr; // ipv4的地址 (通常按网络字节序存)
};接下来的8字节一般填0,在过去是为了对齐,写 0 是为了保持一致、避免未初始化垃圾。
你可能注意到了,我在后面的代码中并没有直接写 addr.sin_port = 8080,而是写了 htons(8080),htons是host to network short的简写,同样还有ntohs,它们的作用是什么?
在大部分的机器使用的是小端法,而网络协议(IP/TCP)为了统一标准,强行规定:网络传输必须使用大端法。因此若是直接sin_port = 8080反而会出错,因此我们引入了htons函数,该函数会根据机器是小端法还是大端法自行对port进行修改,省去了很多功夫。
这个sockaddr_in是要我们自己写然后传进去吗?是的。
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET; // ipv4
addr.sin_port = htons(8080); // port: 8080
addr.sin_addr.s_addr = htonl(INADDR_ANY); // 0.0.0.0 (所有ip都能访问)
if (bind(fd, (struct sockaddr*)&addr, sizeof(addr)) < 0)
{
perror("bind");
close(fd);
return 1;
}bind的返回值为0(成功)或者-1(失败)。
接下来就是listen,监听。
int listen(int sockfd, int backlog);sockfd,就是要监听的fd文件是哪个。
backlog,从accept获取数据最大的排队长度,backlog 满时,不会影响已经建立的连接,但会让新连接建立失败/变慢(表现为 connect 被拒绝或超时)。
在 Linux 现代内核中,这个参数的具体行为比较复杂,CSAPP 中建议将其设为一个较大的常数(如 1024),而不是纠结具体数值。
返回值0(成功)或 -1(失败)。
accept,接收数据,一般用个while循环不断的接收。
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);sockfd,就是前面socket、bind、listen的fd。
addr,如果不填NULL,填入的数据就是接收客户端的地址信息,你一般传入 struct sockaddr_in client; 的地址,然后强转成 struct sockaddr*,填NULL就代表我不关心客户端的信息。
addrlen,传入时,就是告诉内核addr这个缓冲区的大小有多大,当accept结束后,addrlen的长度会被修改,修改为实际使用的长度。
使用情况:
struct sockaddr_in client;
socklen_t len = sizeof(client);
int connfd = accept(listenfd, (struct sockaddr*)&client, &len);注意区分哈,这里的addr是我们从访问我们服务器客户端得到的,而不是我们在上面写的addr。
当accept成功时,服务器会给该成功连接的客户端分配一个临时端口,同时accept会返回一个fd,之后服务器读取、发送信息都通过该fd文件进行。
讲到了服务器的accept,我也讲一下客户端的connect。
int connect(int clientfd, const struct sockaddr *addr, socklen_t addrlen);这三个参数大同小异,connect 中的 addr 是目标服务器的地址,而不是像 bind 那样是本机的地址。
接下来讲述的是TCP握手,很出名的就是TCP的3次握手。
第一次握手,客户端尝试连接服务器,
第二次握手,服务器回应客户端,
第三次握手,客户端成功与服务器建立联系。
如果我们一个ipv6的服务器监听,上面在每一步都或多或少要改点,是否有更现代(对于c来讲较新)、更整洁的方式呢?

使用getaddrinfo得到的数据,比传统的更安全、更通用。
host,ip或者网址。
service,对应端口号
hints,对应的结构式addrinfo:
struct addrinfo
{
int ai_flags; // 额外选项(AI_PASSIVE 等)
int ai_family; // AF_INET / AF_INET6 / AF_UNSPEC ...
int ai_socktype; // SOCK_STREAM(TCP) / SOCK_DGRAM(UDP) ...
int ai_protocol; // IPPROTO_TCP / IPPROTO_UDP / 0 ...
socklen_t ai_addrlen; // ai_addr 指向的地址长度
struct sockaddr *ai_addr; // 具体地址(其实是 sockaddr_in / sockaddr_in6 等)
char *ai_canonname; // 规范化主机名(可选)
struct addrinfo *ai_next; // 下一个候选结果
};ai是addrinfo的缩写,这里留个小任务,你看看这些数据哪些是我们在上面会用到的,你想想哪些是要我们填的,不用全部填完,填一部分即可。
ai_flags,如果服务器端填AI_PASSIVE,当 host == NULL 时: IPv4 会返回 0.0.0.0(监听所有网卡)。
result,就是根据host、service和hints,获得的一系列可能可以的列表,为什么是多个而不是一个?获取的目的网址他可能多个对应的ip,比如google它在全球有多个服务器站点,我们通常使用的是综合考虑较优的那个服务器站点,还有不同网络类型比如ipv4,ipv6,也可能有ipv6拿到了那你连不过去,要尝试ipv4这种情况都有。
ponsde@ser6401954687:~/test$ nslookup www.google.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: www.google.com
Address: 142.250.71.196
Name: www.google.com
Address: 2404:6800:4005:816::2004在result这个链表里,是一系列可能的候选地址。
ai_canonname(规范主机名)一般来讲用不上,你可以自己去查查看什么用处。
在hints我们是不用填next的。
通过这个,我们只需要填入host、service和hints,就能获得我们想要的数据:
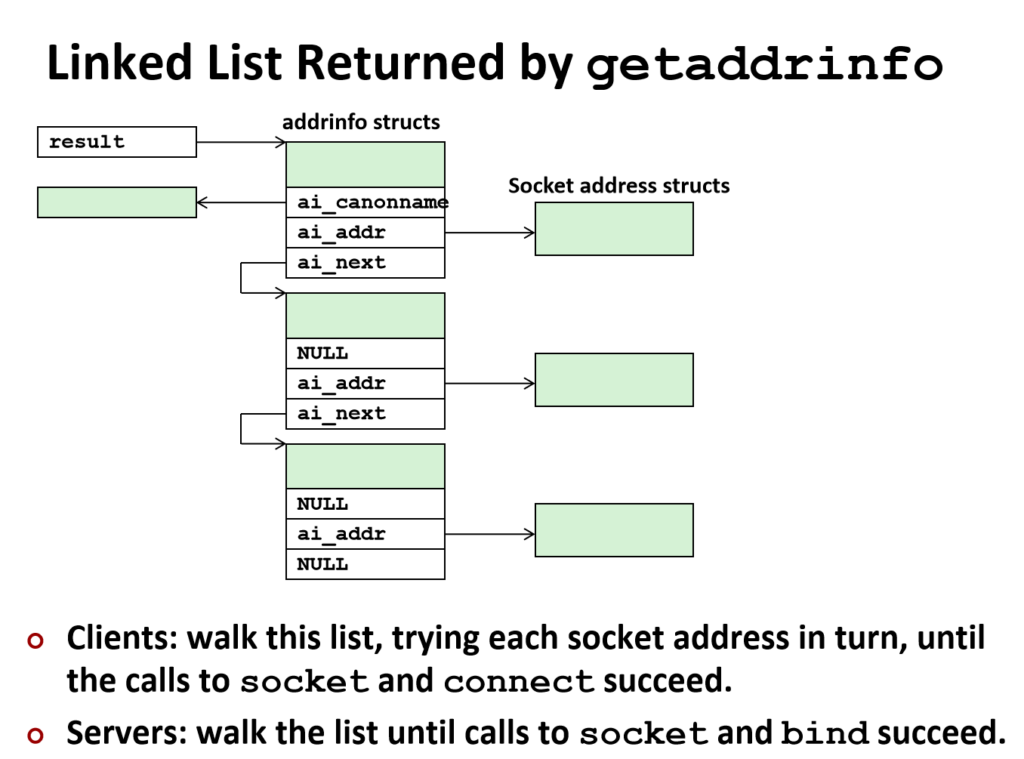
这就是获取的列表,每一个都是待选地址,那通过getaddrinfo得到的数据,我们该怎么用到socket、bind上呢?
getaddrinfo(NULL, port, &hints, &res)
for (p = res; p != NULL; p = p->ai_next)
socket(p->ai_family, p->ai_socktype, p->ai_protocol)
bind(listenfd, p->ai_addr, p->ai_addrlen)
我就不给全部的每个步骤,就给每个怎么用的了。

getnameinfo 是 getaddrinfo 的逆过程。
getaddrinfo 是将主机名/域名转换成Socket地址结构(二进制IP);而 getnameinfo 则是将Socket地址结构转换成主机名或可读的IP字符串。
sa、salen就是socket的addr和len,我想经过上面的讲述你应该挺熟悉了,我就不多赘述了。
host、hostlen和serv、servlen就我们自己提供,它会将解析socket addr后的结果放入其中,若是不需要比如下面的例子,我不关心serv所以填NULL。
flags就是选项,NI_NUMERICHOST代表返回数字的地址,NI_NUMERICSERV就是返回端口,我下面的例子只想要地址,因此flag只选了NI_NUMERICHOST,若是两个都需要,则NI_NUMERICHOST | NI_NUMERICSERV,当然,现在最经常使用的是0,通过前面填入的智能选择。
getaddrinfo通过解析网址(客户端向服务器请求),得到ip,但这个ip是二进制的,而getnameinfo相当于将这个ip转化为人能看懂的形式。
特别需要注意的是c语言没有自动的内存回收,因此需要freeaddrinfo(listp)这样回收内存,不然会内存泄漏。
#define _GNU_SOURCE
#include <stdio.h> // printf, fprintf
#include <stdlib.h> // exit
#include <string.h> // memset
#include <sys/types.h> // 基础类型(有的系统需要)
#include <sys/socket.h> // sockaddr, socklen_t
#include <netdb.h> // getaddrinfo, freeaddrinfo, getnameinfo, gai_strerror, NI_*
int main(int argc, char *argv[])
{
struct addrinfo hints;
struct addrinfo *p, *listp;
char buf[NI_MAXHOST];
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_family = AF_INET;
hints.ai_socktype = SOCK_STREAM;
if (getaddrinfo(argv[1], NULL, &hints, &listp) != 0)
{
fprintf(stderr, "getaddrinfo error: %s\n", gai_strerror(rc));
exit(1);
}
int flag = NI_NUMERICHOST; // 填0也可以
for (p = listp; p != NULL; p = p->ai_next)
{
getnameinfo(p->ai_addr, p->ai_addrlen, buf, NI_MAXHOST, NULL, 0, flag);
printf("%s\n", buf);
}
freeaddrinfo(listp);
exit(0);
}可以先试着看一下能不能理解。
从某种角度来讲,他跟nslookup差不多:
ponsde@ser6401954687:~/test$ nslookup www.google.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: www.google.com
Address: 142.250.71.196
Name: www.google.com
Address: 2404:6800:4005:816::2004
ponsde@ser6401954687:~/test$ ./hostinfo www.google.com
142.250.71.196得到的ip一样(这边的hostinfo只是解析了ipv4的情况)。
或许你可以试着做做几个练习:
你能试着获取某网址的port吗?你能通过ip+port的形式访问网站而不是网址吗?(可以试试我的博客哦)
接下来让我们走进服务器和客户端通过什么传递信息呢?
在建立起TCP连接后,数据通过HTTP的协议在服务器和客户端之间传递。
在我们复制网站连接时,通常会是(https://ponsde.com/)这样的形式,它的开头是https,https是相对于http加入了TLS/SSL证书,在你访问网址时,通过验证证书确定你访问的是正确的地方,并提供数据加密等。

当你打开网址,对应的页面分为静态内容(如固定的文本、图片)和动态内容(如股票实时图),静态内容在服务器上已预先创建好为完整的文件,对所有用户、所有请求都返回相同的内容。,而动态内容根据客户端传入的数据而更新,可以根据用户的不同提供不同的内容。
比如我这个博客时wordpress做的,他就是动态内容,也有静态的博客,它提供静态内容。当你查看我的文章时,你能看到那边的小眼睛查看次数会增加,这是在动态博客的数据库里增加了查询次数,当你访问我的博客时,得到的是根据当时数据生成的全新页面,而静态博客就不容易做到这一点,因为它每次给所有用户返回的内容是一样的,虽然有别的方法能另类实现,但也不太容易做到真正的实时更新。
当然一个界面不是全为动态或全为静态,比如我文章内容能算是静态,因为每个人看到的都一样,但浏览量数字、评论区等是动态,根据每次查询数据库而进行显示。
HTTP能返回的类型分为:
text/html(HTML文档)
text/plain(无格式文件,就好像txt文本)
image/gif(gif图像)
image/png(png图像)
image/jpeg(jpeg图像)

http://www.cmu.edu:80/index.html
(http://www.cmu.edu:80) 部分可以看作是前缀,获得服务器的协议类型(HTTP)、服务器地址(www.cmu.edu)和端口(80),(/index.html)部分可以看作是后缀,即该去哪一个区域找这一文件,注意比如test/test1,是在test目录里找test1这个文件。
我们可以在与服务器建立TCP联系后,通过一行<method><uri><version>和多行请求头的形式进行请求。
<method>:GET, POST, OPTIONS, HEAD, PUT, DELETE 和 TRACE
uri是一个标识符,他和url很像但功能不同,uri是标识资源的是什么而url是定位资源并能进行访问,比如/index.html是uri,但它不是url,因为它不是完整的http://www.cmu.edu:80/index.html,而完整的这个地址是url。
<version>:HTTP的版本,比如HTTP/1.0和HTTP/1.1
请求头有很多,这边以Host为例,当你第一行输完后,还需要在输入Host,因为一个服务器可能托管了多个网址,你需要输入Host确认是哪个网址,比如:
ponsde@ser6401954687:~$ telnet www.cs.cmu.edu 80
Trying 128.2.42.95...
Connected to SCS-WEB-LB.ANDREW.cmu.edu.
Escape character is '^]'.
GET /~bryant/test.html HTTP/1.1
Host: www.cs.cmu.edu
HTTP/1.1 200 OK
Date: Wed, 24 Dec 2025 06:54:19 GMT
Server: Apache/2.4.18 (Ubuntu)
Set-Cookie: SHIBLOCATION=tilde; path=/; domain=.cs.cmu.edu
Accept-Ranges: bytes
Vary: Accept-Encoding
Content-Length: 479
Content-Type: text/html
Set-Cookie: BALANCEID=balancer.web38.srv.cs.cmu.edu; path=/;
Set-Cookie: BIGipServer~SCS~cs-userdir-pool-80=550109824.20480.0000; path=/; Httponly
<html>
<head><title>Some Tests</title></head>
<body>
<h1>Some Tests</h1>
<ul>
<li><a href="index.html">Bryant's Home</a>
<li><a href="http://csapp.cs.cmu.edu">CSAPP</a>
<li><a href="nothing.html">Nonexistent file</a>
<li><a href="http://www.nowhere.cs.cmu.edu">Nonexistent host</a>
<li><a href="http://www.google.com">Google</a>
<li><a href="http://www.cmu.edu">CMU</a>
<li><a href="http://www.yahoo.com">Yahoo</a>
<li><a href="http://www.nfl.com">NFL</a>
</ul>
</body>
</html>
Connection closed by foreign host.我们进行了一次成功的连接。
HTTP/1.1 200 OK
Date: Wed, 24 Dec 2025 06:54:19 GMT
Server: Apache/2.4.18 (Ubuntu)
Set-Cookie: SHIBLOCATION=tilde; path=/; domain=.cs.cmu.edu
Accept-Ranges: bytes
Vary: Accept-Encoding
Content-Length: 479
Content-Type: text/html
Set-Cookie: BALANCEID=balancer.web38.srv.cs.cmu.edu; path=/;
Set-Cookie: BIGipServer~SCS~cs-userdir-pool-80=550109824.20480.0000; path=/; Httponly服务器回应行的第一行写明了HTTP的版本、状态。

状态分为3种,200(成功),301(重定向,比如http的网址加了证书变成了https,这时候你访问http网址就会重定向到https的网址)和404(未找到)。
Content-Length: 479
Content-Type: text/html还有文本的种类和长度,该文本为html文本。
你是否产生了好奇,好奇它怎么正确响应请求的?
让我们看一个简单的Tiny Web server。

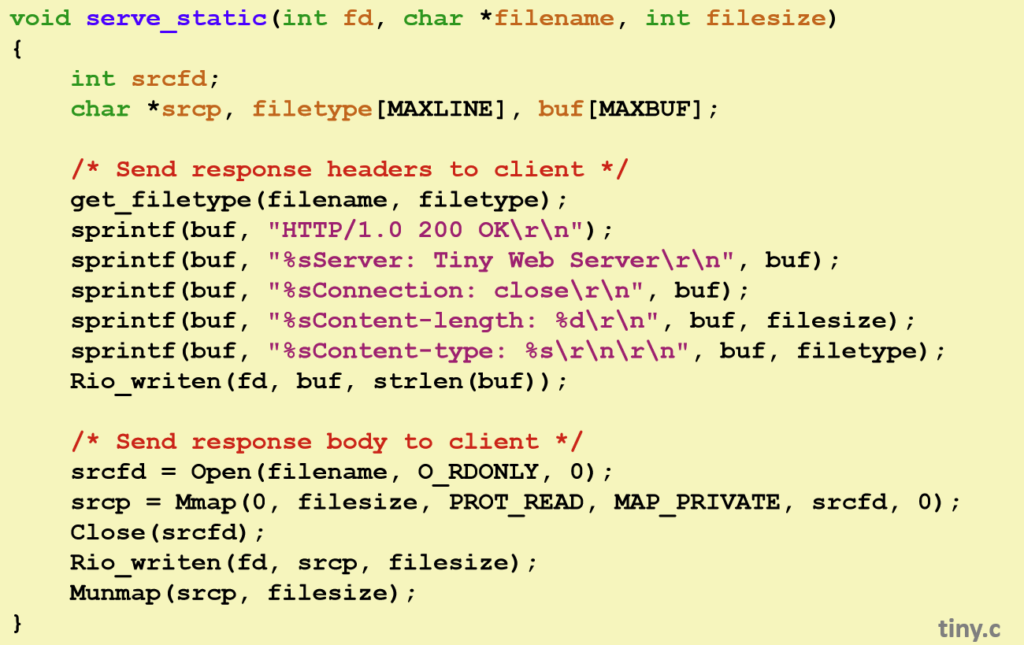
让我们通过分析这个代码,带你明白静态内容是怎么返回的。
serve_static接受3个参数,fd(accept返回得到的客户端描述文件),filename(GET那一行填写的uri),filesize。
通过get_filetype函数得到该文件的类型(如text/html)并放入filetype。
它是怎么通过文件名得到类型的呢?简单的看文件的后缀:
void get_filetype(char *filename, char *filetype)
{
if (strstr(filename, ".html"))
strcpy(filetype, "text/html");
else if (strstr(filename, ".gif"))
strcpy(filetype, "image/gif");
else if (strstr(filename, ".png"))
strcpy(filetype, "image/png");
else if (strstr(filename, ".jpg"))
strcpy(filetype, "image/jpeg");
else
strcpy(filetype, "text/plain");
}非常的朴实无华。
sprintf,将第二个参数写入第一个参数,覆盖掉原先的第一个参数,因此第一行buf内的垃圾值被覆盖了,然后从第二行开始,每一行都有%s,将上一行的buf的结果放在了开头,因此做到了连续存入的效果。
你是否注意到了\r\n,这是它固定的格式,表示一行结束/换行,它的要求很严格,你若是不这么满足这个要求,它就死给你看,当\r\n\r\n时,代表结束。
rio_writen,就是将buf内的内容写到fd中。
mmap,将磁盘中文件的内容映射到内存,但当调用函数结束时,内存中并没有对应的内容,但调用时产生缺页异常,然后os系统去获取内容,相当于隐式调用了read。
mmap的6个参数:
addr(期望映射到的虚拟地址,填0代表智能选择)
length(映射的大小,字节数)
prot(这块内存允许什么访问权限,比如PROT_READ,只读映射文件内容)
flags(映射的类型,比如MAP_PRIVATE:你写这块内存不会改到文件,也不会影响别的进程)
fd(要映射的文件描述符)
offset(偏移量,从文件的哪里开始,填0代表从头开始)
munmap函数,将映射清除掉。
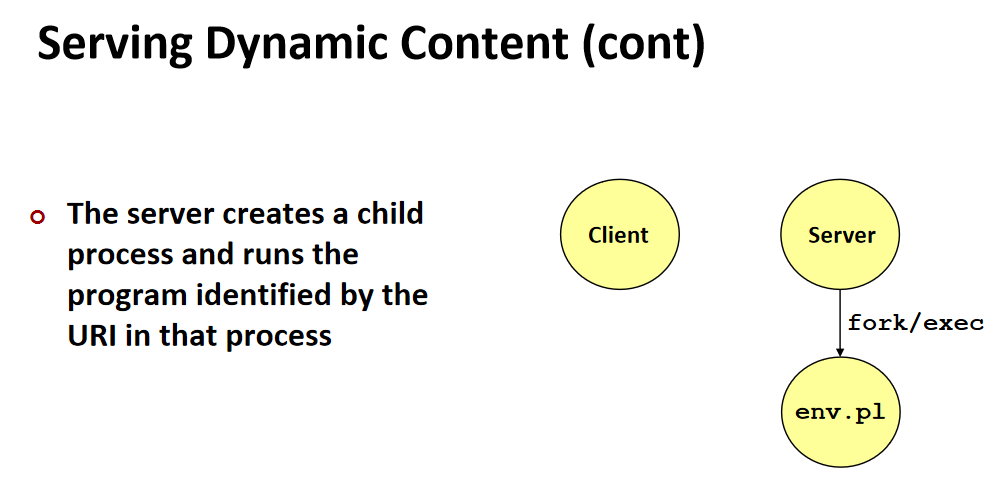
静态内容的获取就这么简单,接下来让我们看看动态的,当uri中包含/cgi-bin,代表这次请求是个动态内容,服务器通过fork和exec来进行:
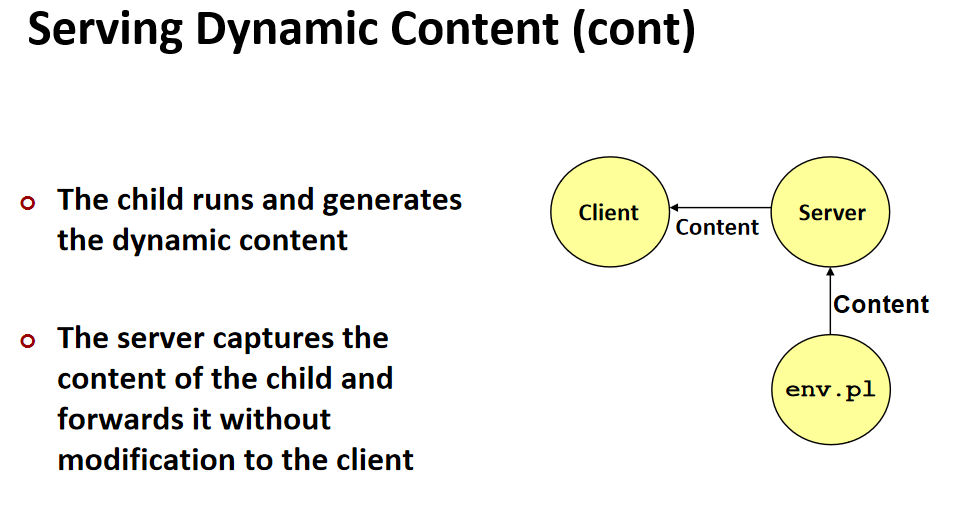
然后子进程将结果发送到客户端即可:
动态内容不只是“运行程序”这么简单,关键在于参数和信息如何在三者之间传递,因此通过一套CGI规则来实现规范(现在其实有点过时了,因为很多简单的事情如果都要fork和exec来解决就太糟糕了)。
我们通过一个简单的动态请求:传入两个参数,并计算它们的和:

?代表参数列表的开始,&分割参数,空格可以用’+’或者’%20’表示,该图没有显示。
服务器里不一定有叫cgi-bin的文件夹,/cgi-bin/ 本质上是一个“URL 前缀/路径约定”:Web 服务器看到请求路径以它开头,就把它当作 CGI 动态程序 去执行,而不是当作普通静态文件去读出来。
实现的效果:
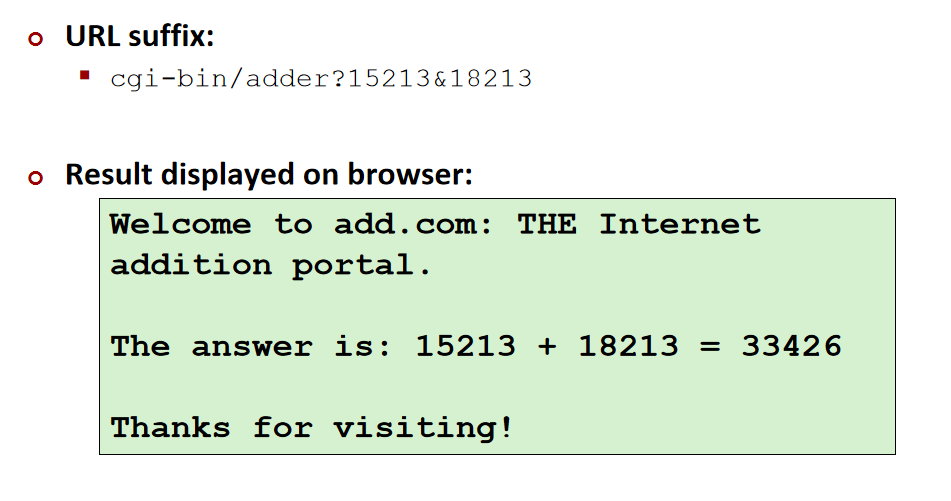
服务器是怎么传递这两个参数的呢?
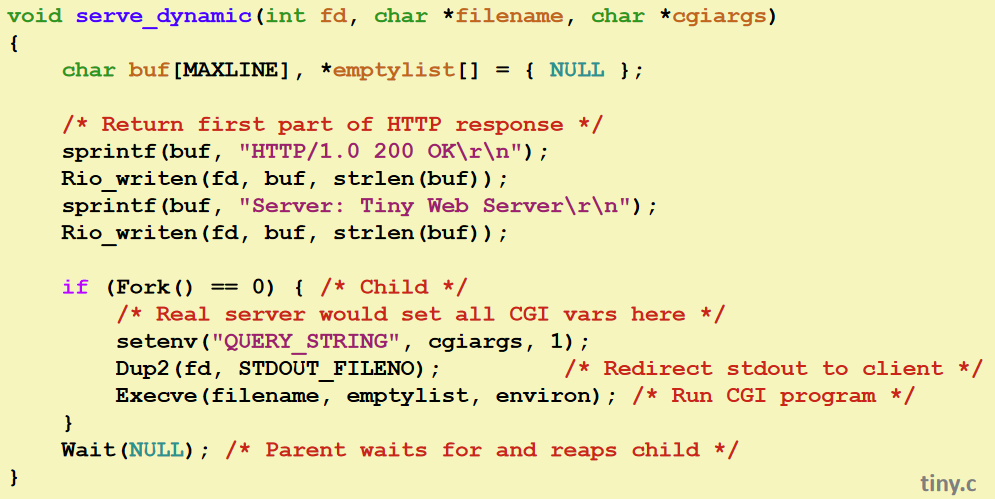
在动态请求中,进行fork,当fork=0,即子进程,通过execve执行addr。
在此之前,通过setenv,将?之后的内容填入QUERY_STRING,第三个参数非0(一般写1)代表若有重复则覆盖,0则是不覆盖。
Dup2则是将子进程的STDOUT_FILENO的指向改为fd,就是子进程进行print时,因为STDOUT_FILENO被改成了fd,因此输出的内容会写到fd中,然后在客户端那显现。
结束后,子进程改头换面去执行addr。
父进程最后的wait是回收子进程,避免僵尸进程。

QUERY_STRING(环境变量) 里放的是uri里?后面的那一整段字符串(不包含?本身)。
strchr将p指针定位到&,然后将&替换为‘\0’,此时两个参数就分开了,再通过strcpy,atoi,将字符串转换为数字即可。
这时候分割参数成功了就要开始继续:

最后将内容输出,但因为STDOUT_FILENO被修改,因此客户端那收到信息。
好咯,差不多讲完了,完结撒花*★,°*:.☆( ̄▽ ̄)/$:*.°★* 。









