
服务器接收到客户端发来的请求时,forkk()一个子进程来负责该客户端,而父进程保持持续的监听,直到下一个客户端发送请求,在fork()一个子进程来负责:
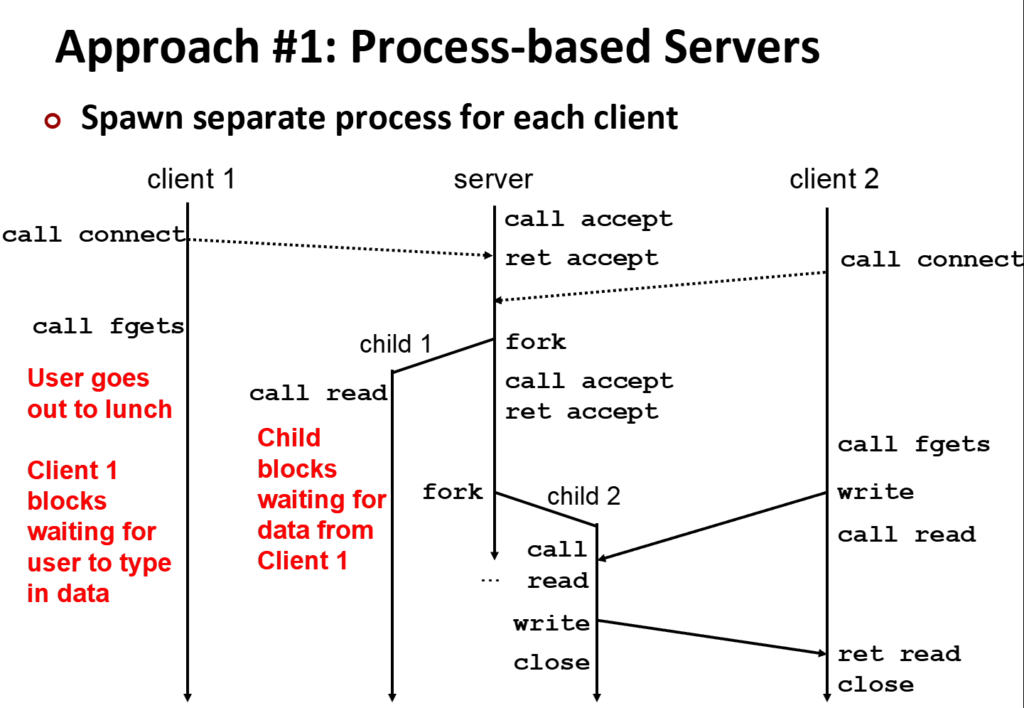
这就是很典型的基础进程模型,基于进程的特点是进程间相互隔离,互不影响,因此稳定性高,如浏览器的标签页,它们每一个都是一个子进程,以此来维护稳定的浏览体验,以至于一 个网页崩了就全崩了。
它的缺点也很明显,当进程接收每一个来自客户端的请求都会进行fork(),而每一个子进程创建(如页表的复制、内核资源的空间)和切换身份(A程序开始执行B,)都会占用大量的os资源,当客户端的请求很简单比如传入1和1,让服务器计算1+1,这种分裂一个子进程出来执行的成本会非常大,所以很不划算,同时不同的进程间传信也十分的艰难。
因此让我们转向另一个,基于事件。
当客户端向服务器发出请求时,它不分裂一个子进程,而是通过select函数(现在更多的是epoll,epoll更加高效),对每个客户端请求产生的connfd进行选择,select通过传入的x秒时间参数,在调用select函数时,监听x秒,然后写入监听的结果,通过分析结果得到那些客户端是活跃的正在请求,哪些是沉寂的,哪些已经关闭了连接,该connfd可以移去的。
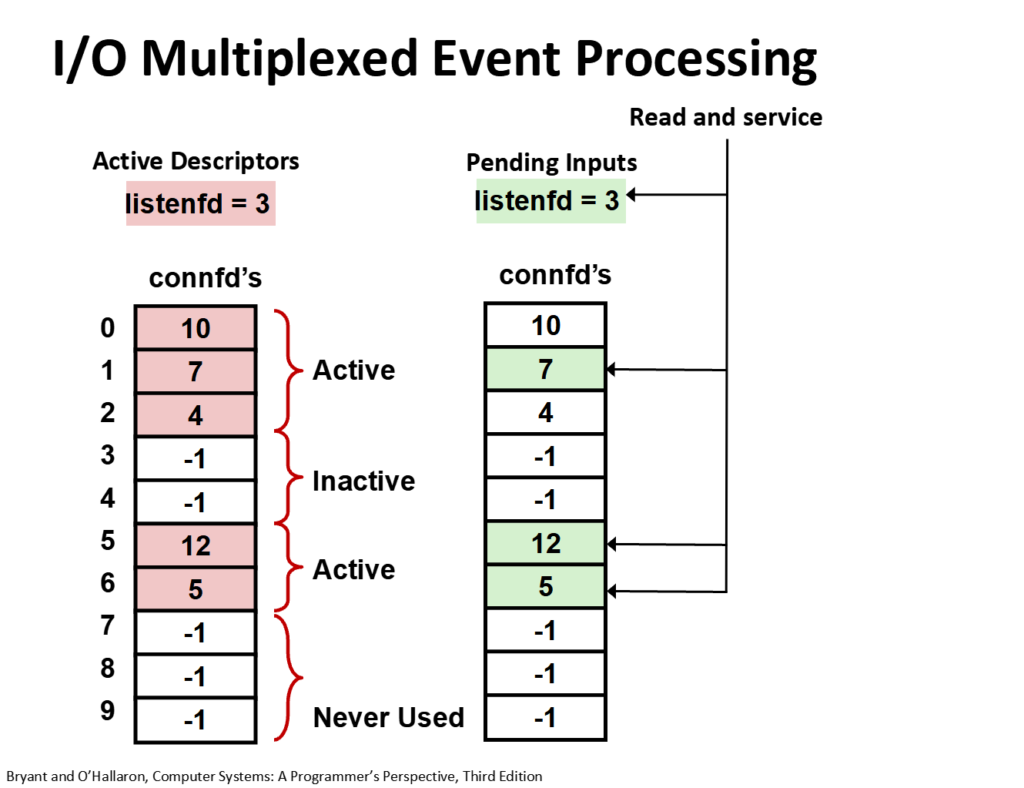
该行为始终在一个内存中进行,因此对os资源的消耗小,但缺点是在单个cpu核心中进行,不能很好的发挥cpu的多核效率,同时对程序员不是很友好,编写代码难度较大。
然后是吸取了二者的部分优点的基于线程。
你是否烦恼于进程的消耗大,通信困难!是否烦恼于事件的多核利用率低!
线程堂堂登场,它拥有资源占用较小、内存共享、多核执行等优点。
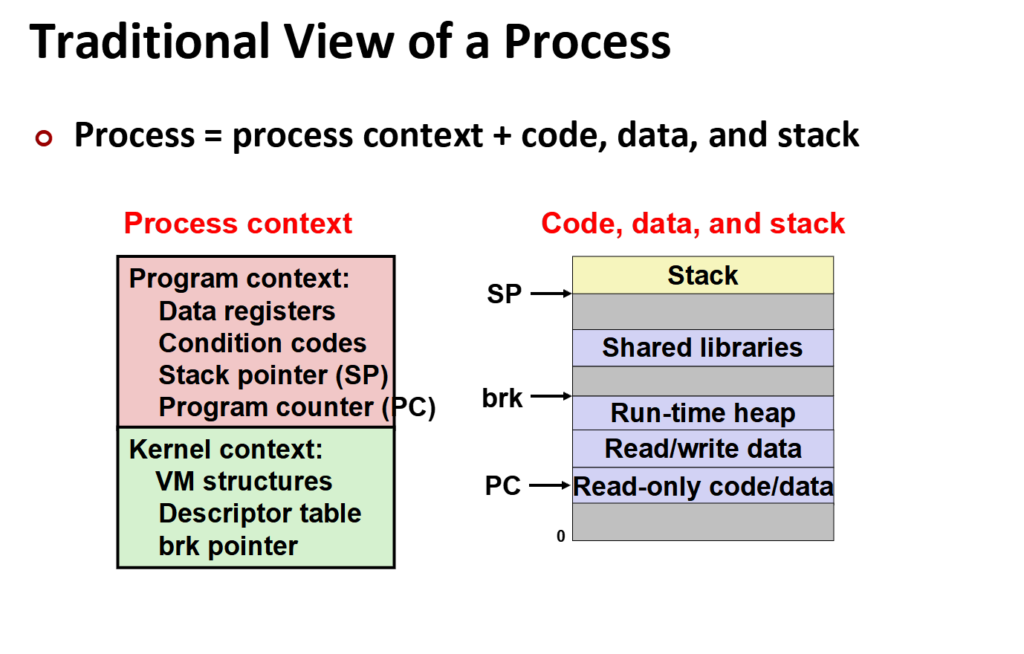
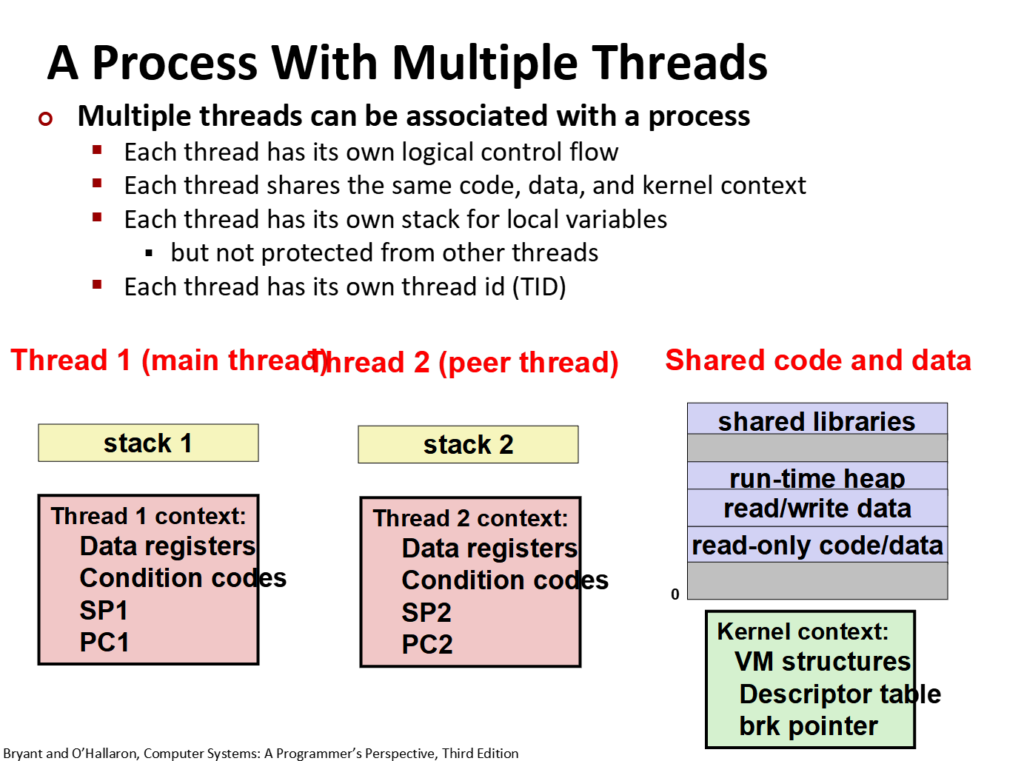
这是传统视角下的认识,我们分为代码程序、内核上下文,虚拟内存,每个进程皆为这三部分,三者缺一不可。
(这里的PC不是指它有自己的硬件PC,而是指令地址这样)
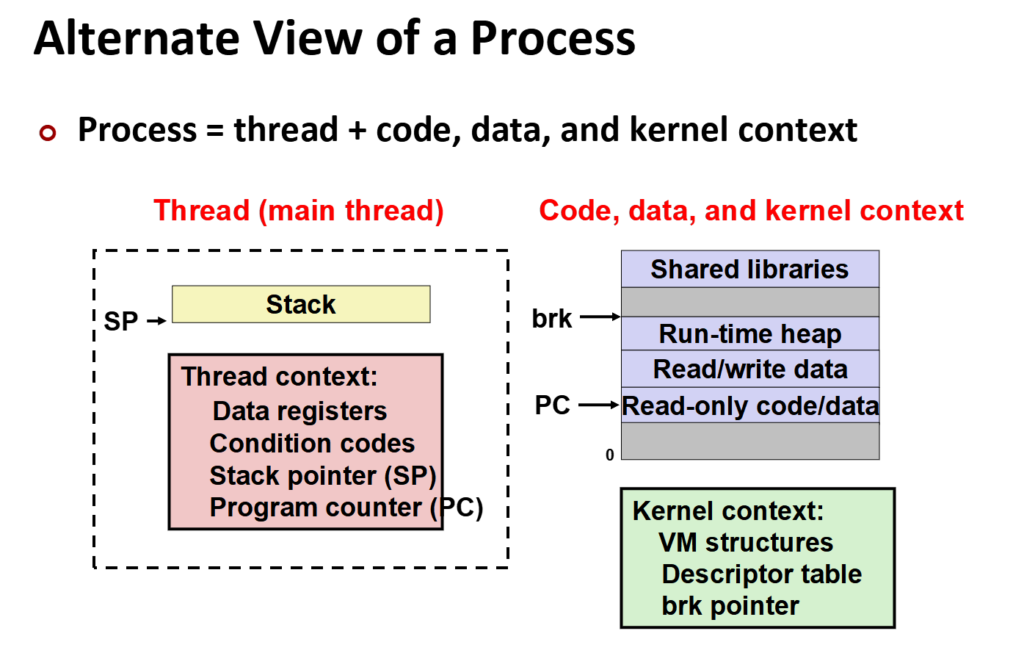
在新的视角下,虚拟内存不再是一整块,而是可以分割成一块块(将原本一大块给存放任务的空间分给了多个线程,让它们存放独属于自己的任务)。
我们将每个线程在虚拟内存中分配独属于它的栈空间,该空间(线程上下文)包含着自己任务相关的信息如局部变量、指令地址等。
因为不同的线程共处于一个内存,因此通过栈来保护线程自己的上下文,而内核上下文(如打开的文件)、数据段(如全局变量)、堆等共享。
有了线程,在单个进程可以进行多个线程,每个线程能执行不同的任务,达成了单个进程进行多个人物的效果。
使用效果如图:
通过这样,一个进程就能通过多个线程来执行多个不同的任务了。
在这里让我引入并发和并行这两个概念。
并发可以看作是一个闪电侠,通过极快的速度,让你看来多个任务在同时进行。
并行是分身之术,让多个人执行任务。
他们的效果看起来都是多个任务的进度都在往前推进。
现实中更多的是并行和并发共同执行来提高效率,就像多个闪电侠执行任务一样。
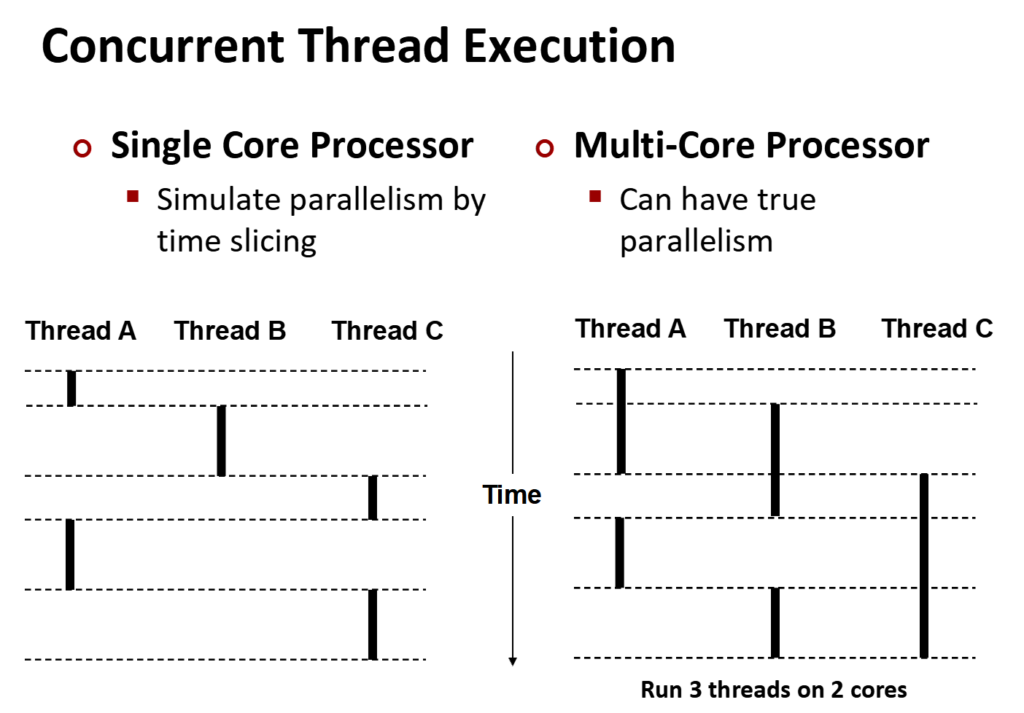
在这张图能看出:
左边的单核,虽然多个任务的进度都在往前推,但每个时间段只有一个任务在推进度,这三根黑线从来没有在同一水平线上重叠过。
右边的多核,在某个时间段有多个任务在同时推进。
让我们回归实际,从代码的角度看看线程是创造、执行任务的。
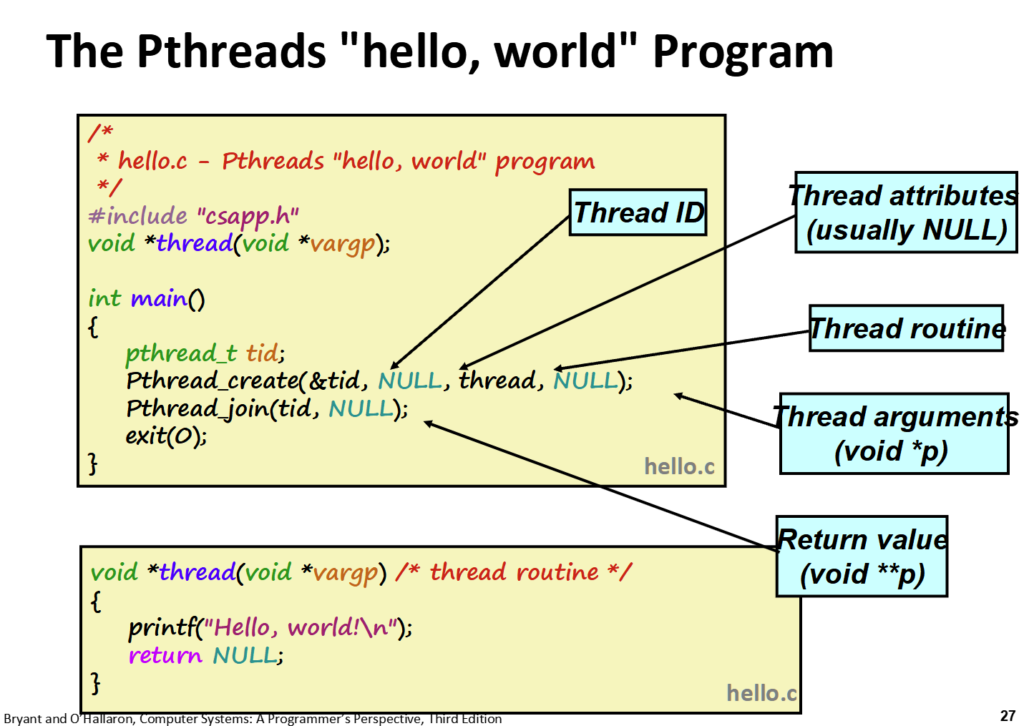
每一个全新的开始都是hello,world。
pthread_create接收4个参数。
参数1为创造的线程id,它会将其写入你传入的参数的位置,
参数2为你对该线程的特殊要求,比如现在线程的内存占用大小等,一般填NULL表示使用默认参数。
参数3为你需要该线程执行的任务,这里要执行的函数名叫thread,因此传入thread。
参数4为需要往该任务传入的参数,就像函数的参数里传入的参数,填NULL表示不传入参数。
这里需要注意的是,thread函数中参数即便不用也不能省略,同时因为pthread_create只能传递一个参数,因此该函数也只能接收一个参数,参数的类型为void*,代表它接收一个地址,该地址对应的值该怎么转换由你决定,这是为了通用性,避免出现错误转换等情况,将转换权交出。
pthread_join就像waitpid,负责回收线程。
参数1为线程的id,
参数2填NULL代表不关注该线程返回了什么,若是你想储存线程的返回,那就传入你想存放的地方的地址。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void* worker(void* arg)
{
int result = 999;
printf("子线程: result在地址 %p\n", &result);
return &result;
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, worker, NULL);
// 准备一个指针变量,用来存放子线程返回出来的地址
void* final_adress;
// 传入这个指针变量的地址 (&final_adress)
// 这样 join 函数就能修改 final_adress 的值了
pthread_join(tid, &final_adress);
int* final_result = (int*)final_adress;
printf("主线程: result: %d (地址 %p)\n", *final_result, final_result);
return 0;
}这段代码很简单,创造一个子进程,该子线程返回储存着值999的变量地址,然后主线程打印值和值的地址,看起来没有任何问题…吗?
注意看,子线程中的result为局部变量,储存在子线程的栈空间里,当子线程被销毁时,这个变量也就被销毁,因此你这个内存地址对应的是个垃圾值(该空间被其他线程使用)或正确的值(未被其他使用),所以不要这样。
那我们该怎么合理的进行呢?
在上面我们提到了堆不是位于线程栈空间内,而是外界共享区域,因此方法为malloc,当你在子线程对该数据进行malloc,当子线程被销毁时,所传递的地址也是安全的地址。
void* worker(void* arg)
{
int* result = malloc(sizeof(int)); // 给该地址分配一个空间,注意要手动回收
*result = 999;
printf("子线程: result在地址 %p\n", result);
return result;
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, worker, NULL);
void* final_adress;
pthread_join(tid, &final_adress);
int* final_result = (int*)final_adress;
printf("主线程: result: %d (地址 %p)\n", *final_result, final_result);
free(final_result); // 记得free,避免内存泄漏
return 0;
}
那我们再换个例子,例如:
void* sample(void* a)
{
return 2倍的a;
}在经历上一个后,我们对它正确的代码是传入a的地址,然后解引用地址,计算2 * a后返回结果:
int val_a = *(int)a;
return 2 * a;但其实还有另一个骚操作,总所周知c语言函数的参数是按值传递,也就是复制,那我们可否不传地址而是直接传a的值呢?这样不就少了解引用这一步了?可以的!事实上很简单,就是将你要传递的那个数转化为void*类型,等传递过去再转化回来:
long a = 1; // 用long是因为其字节数与地址相同。
pthread_create(&pid, NULL, sample, (void*)a);void* sample(void* a)
{
long val_a = (long)a;
return (void*)(2 * val_a);
}这就是一次成功的传递了。
很好!我们现在理解了基础的线程是该怎么运作的,让我们计算1亿个1相加的结果试试。
int sum = 0; // 加上volatile就为 volatile int sum
void* worker(void* arg)
{
long cnt = 0;
for (int i = 0; i < 1000000; ++i)
{
sum += 1;
cnt += 1;
}
return (void*)cnt;
}
int main(void)
{
pthread_t pids[100];
for (int i = 0; i < 100; ++i) // 创造100个线程处理
{
pthread_create(&pids[i], NULL, worker, NULL);
}
for (int i = 0; i < 100; ++i) // 回收100个线程
{
void* result;
pthread_join(pids[i], &result);
printf("线程%lu, 加了%ld", pids[i], (long)result); // 打印100个线程各自处理了多少个数
}
printf("sum:%d", sum);
}看起来没啥问题吧?
这里的sum我没有加volatile(volatile的意为让程序每次读取都老老实实访问内存),因此编译器会对它进行优化,会先将sum的值copy,然后在该函数加完再放回去,效果类似:
void* worker(void* arg)
{
long k = sum; // 复制sum的值,避免for循环相加导致多次访存
long cnt = 0;
for (int i = 0; i < 1000000; ++i)
{
k += 1;
cnt += 1;
}
sum = k; // 写入
return (void*)cnt;
}可以看作如果没加volatile,当线程访问sum为0时,会先加0写入到自己的局部,再吭哧吭哧加个1000000后,再将这100万写入到sum中,这是编译器自己执行的优化。
这下一眼看出了问题?因为编译器自作聪明的优化,导致最后sum = k,若每个线程读取的k都是0,当最后写入时sum只会等于100万。
那我们在sum前面加上volatile呢?这样就能让编译器不自作聪明的优化,而是老老实实的每一次加都访存,加上1,重复,这下没问题了吧?
看上去非常美好,我们让每个线程加100万,将一个任务分成了100个,然后让每个线程进行,但是!这就会出现很重大的问题,也就是线程那严重的缺点,race(竞争),由于每个线程都是平等的,因此在进行访存然后+1时,它们的顺序是没有变化的,因此就会出现:
线程1访存拿到了sum,在循环内+1,写回,sum成功+1,但在这个操作的过程中,也就是线程1访存拿到sum后,写回前,线程2访存拿到了sum,然后sum + 1, 写回,当线程1往内存中写回导致sum + 1时,线程2也往内存中写回,写回了与线程1相同的值,理论上线程1和线程2执行完的结果是sum + 2,但实际上只进行了sum + 1,这就发生了一次竞争,竞争的发生导致了错误的执行结果。
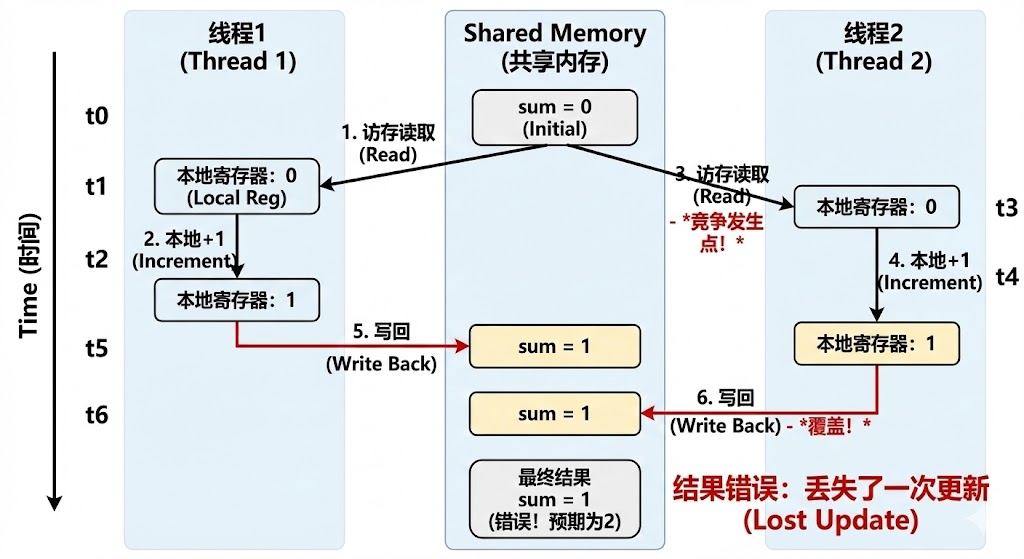
而线程又是平等的,不能在创建线程时分配哪个先哪个后,因此,出现了新的方法,锁。
锁的目的就是当该区域被某个程序执行时,该程序拿到了锁,其他的程序若是要涉及该区域,需要等该程序执行完,把锁放下才能涉足该区域。

P、V信号,可以看作最初的锁。
s(sem_t)代表的余量,s始终不为负数,当s为0时,代表没有容量了,若是其他程序需要执行,需要等空余的容量。
P(sem_wait()),就是进行拿锁的操作,当程序执行P(s)后,s减1,若s已经为0了,线程就会停滞,直到余量大于0。
V(sem_post()),就是放下锁的操作,当程序执行后,s加1。
这两个操作构成了最基本的锁。
在使用前我们需要先初始化s,也就是余量为多少:
sem_init(&s, 0, 1);
第1个参数就是sem_t,需要我们提前创造。
第2个参数,若为0代表线程共享,若不为0代表进程共享,就是锁的作用范围。
第3个参数就是余量了,填1代表余量为1。
而正常的使用就为:
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
int sum = 0;
sem_t s;
void *worker(void *arg)
{
long cnt = 0;
sem_wait(&s); // 拿锁
for (int i = 0; i < 1000000; ++i)
{
sum += 1;
cnt += 1;
}
sem_post(&s); // 放锁
return (void *)cnt;
}
int main(void)
{
sem_init(&s, 0, 1); // 初始化锁
pthread_t pids[100];
for (int i = 0; i < 100; ++i)
{
pthread_create(&pids[i], NULL, worker, NULL);
}
for (int i = 0; i < 100; ++i)
{
void *result;
pthread_join(pids[i], &result);
printf("线程%lu, 加了%ld\n", pids[i], (long)result);
}
printf("sum:%d\n", sum);
}这就是一次正确的相加。
你可能注意到了我把拿锁和放锁放在了for循环外,因为这样的效率更高,放在for循环内属于细颗粒度,每一次访存都进行加锁、放锁,由于os调用也是需要时间的,放在for循环外的粗颗粒度的速度更快,细颗粒度进行了100万次的加锁、放锁,而粗颗粒度只进行了2次加锁和放锁。
但因为这样的操作反而不如单个程序直接for循环累加来的好,因为它这里没能实现多线程同步而是依次进行。
我们最常用的是互斥锁, 也就是区域内只能容纳有一个程序的锁,在 99% 的开发场景(多线程)下,你只需要记住这两个最简单初始化的写法就够了。
// 两种初始化的方法,填NULL为线程间共享
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, NULL)
// PTHREAD_MUTEX_INITIALIZER 是个宏,像sem_init初始化一样直接赋值初始状态,
// 默认是 PTHREAD_PROCESS_PRIVATE(线程间共享(即进程私有))
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_lock(&lock);
pthread_mutex_unlock(&lock);你是否听说过死锁、饥饿这些词?
死锁:
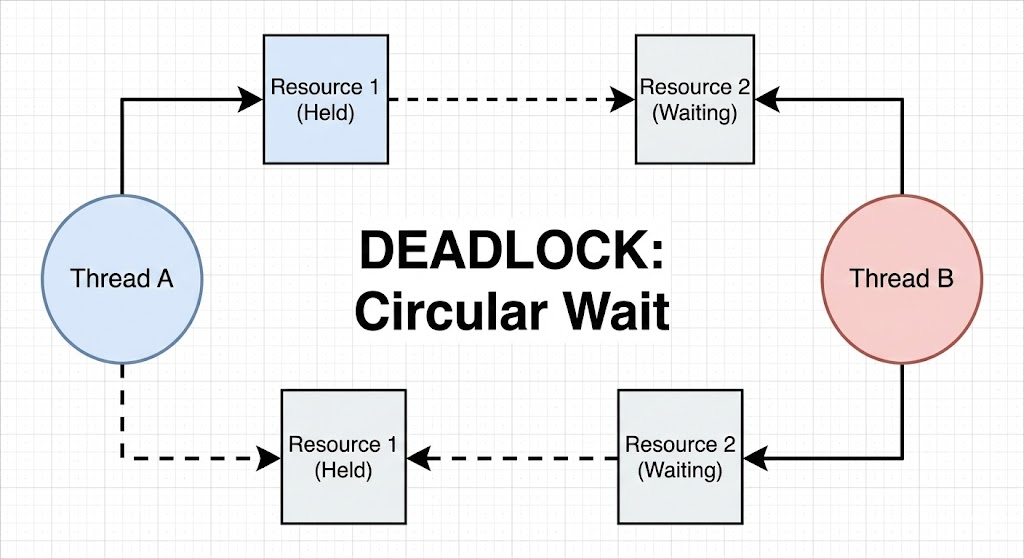
是否觉得太宽泛,让我们看个具体的例子:
就像不要在信号里使用printf一样,stdio是有锁的,也就是说当一个程序在打印时,其他程序要等它结束才能进行,假设你在检测ctrl+c信号的执行中加入了printf打印,当在一个恰当的时机,你刚好在某个程序执行printf,它拿到了stdio的锁,还没放下,你信号的插入导致中止,但锁还是拿着的,信号中使用了printf,也要去拿stdio的锁,但你需要等锁被拿下,这就出现了巨大的问题,死锁!
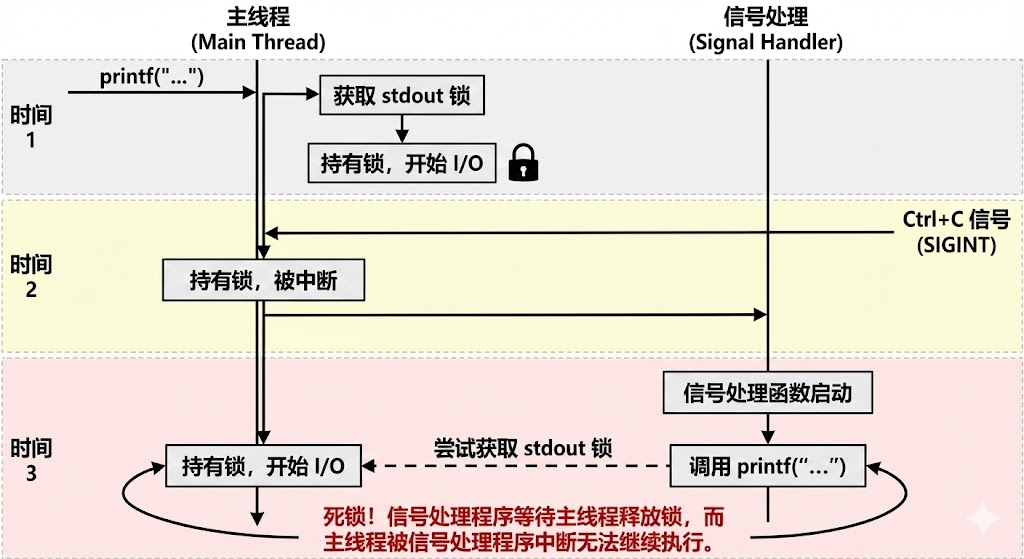
因此我们定义了可重入函数和不可重入函数。
可重入函数在被执行到一半时被打断(如中断、信号、线程切换),然后再次被调用(重入),依然能正确运行,且不会搞坏之前那次执行的数据。
不可重入,就是指一个函数在执行过程中被中断,然后又被重新调用(重入),会导致内部状态混乱或死锁。
饥饿:
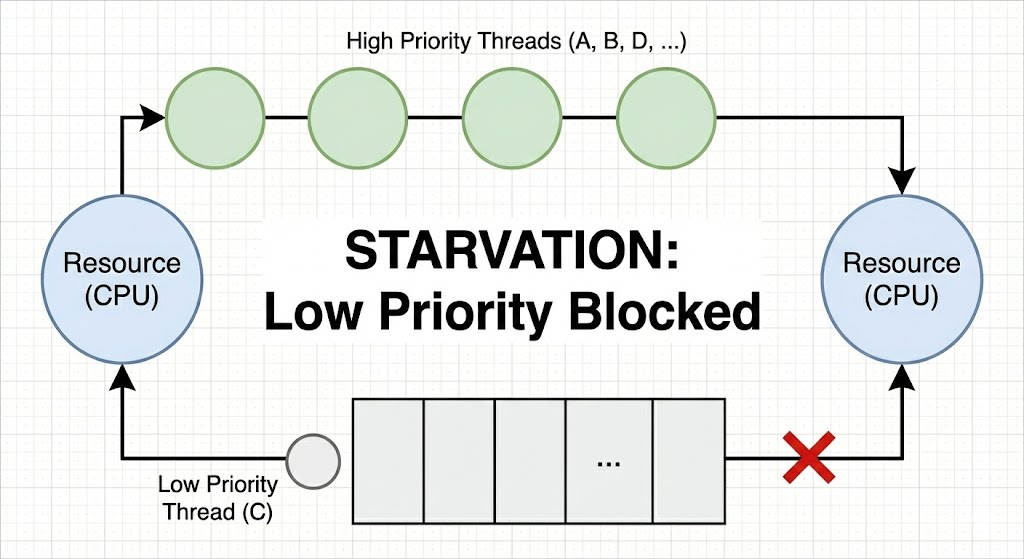
优先级低的需要等优先级高的先进行,若是优先级高的源源不断,就会导致优先级低的一直在等待,它会被“饿死”。
就像这个例子:

当有读者在时,写者就要一直等,只要读者能持续的接替,就会导致写者需要一直等下去。
好咯,接下来让我们接着来看。
在现代cpu,多核已经是常态:
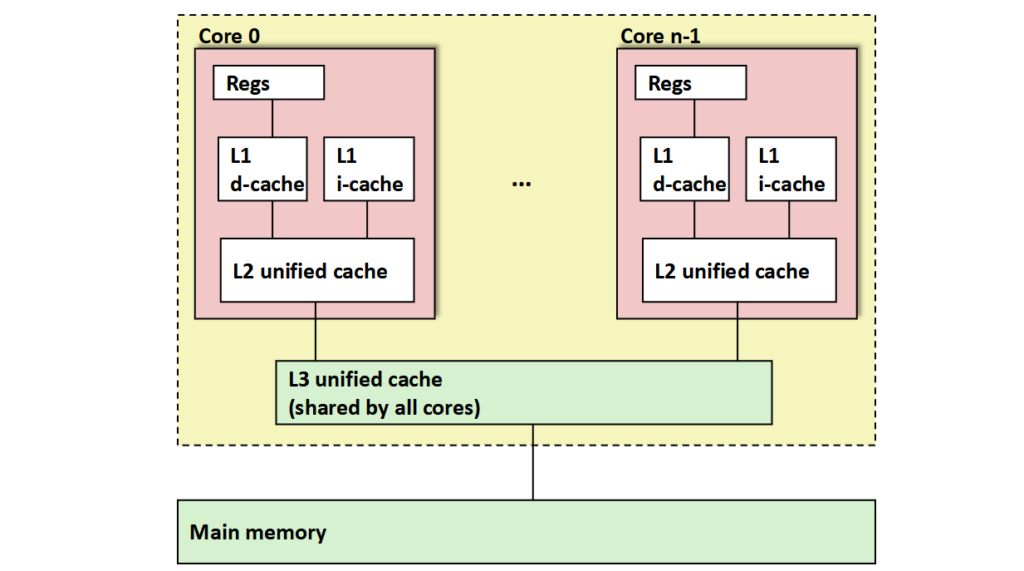
i-cache,存放指令,d-cache,存放数据。
unified cache,统一缓存,不区分
而cpu的执行,高效率的秘诀是乱序执行:
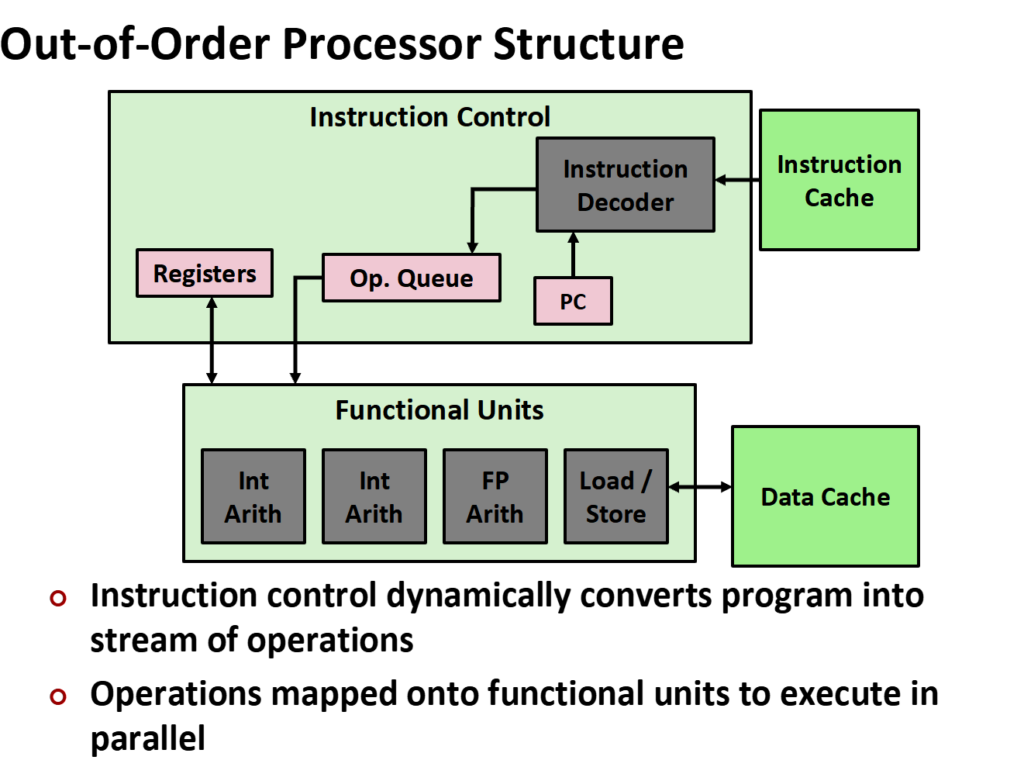
i.cache和PC通过指令解码器解码后放入操作队列中,这个过程持续进行,而不是等待上一条指令结束后再继续往队列中放入下一行指令,当判断到某个指令可以执行就先执行,不必严格按照顺序来。
例如上一条指令还在访存,此时下一条指令是计算,而此时计算单元是空出来的,cpu就会顺带执行计算指令,这就完成了一次乱序执行,但单纯乱序不可取,存在ROB记录指令的位置,当指令完成后根据ROB的顺序执行,假设10条,后9条完成了,第1条没完成,就要等第一条完成了才行,因此在程序看来是顺序进行下来的。
这也带来的一次巨大的事件,叫幽灵熔断事件,是基于cpu的乱序执行和分支预测进行的。
if (程序员不是人类) {
val = 密钥; // 程序员是人类,因此不应该执行
}在这里,黑客通过特定的手段,让cpu错误的预测执行了这一段指令,当if中结果出现,cpu发现预测错误,撤回了操作,也就是ROB中,错误预测后续的指令都舍去了,但是,cpu为了提高效率,不会把错误预测的数据抹去,而是当作垃圾值,之后会直接将其覆盖,但错误预测的数据已经存在了d-cache中了。
黑客正是借用这个,让cpu通过错误预测,然后通过查询各种地址,通过速度快慢(在d-cache的数据获得速度很快)的判断错误预测读取的数据是哪些,从而得到想要的。
题外话讲完了让我们继续。
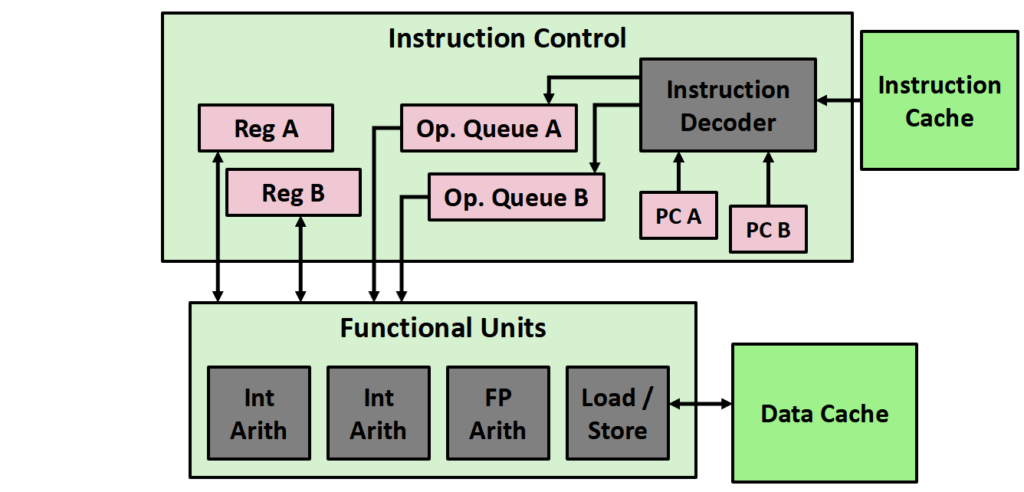
在现在会采用一核多线程的方式,也就是在硬件上另一份PC等,从而实现更高的效率(如线程A的所有指令都在访存,此时线程B就能通过使用计算单元在这段缝隙时间加快效率)。
你是否有好奇既然线程增加效率会增加,那如果加很多呢?
这就像cpu的流水线,流水线过多了效率也没过高,Intel就在这翻过车,有兴趣的可以查查。
因为d-cache的大小是固定的并且小的,如果线程过多会导致某个线程的数据被其他线程覆盖了,但数据该线程还没用,只能在算一次。
我们可以把 L1/L2 Cache 想象成一张 “办公桌”:
- 单线程:你一个人用一张桌子。你的书、草稿纸(数据)铺满桌子,伸手就能拿到,效率极高。
- 双线程 (SMT):两个人共用一张桌子。稍微挤一点,但如果你在发呆(等内存),我就用桌子写字。勉强能接受。
- 100 个线程:
- 线程 A 刚把它的书铺好,准备算加法。
- 上下文切换 (Context Switch) 来了,线程 B 进场。
- 线程 B 把线程 A 的书全部扫到地上(Evict/Invalidate),铺上自己的书。
- 轮到线程 A 回来时,发现书都没了(Cache Miss),只能重新去书架(内存)拿。
上面这段来自gemini,很形象。
在特殊情况如某些需要频繁访存的机器(GPU),这时候线程多是好事,因为频繁的访存,它靠海量的线程来彻底掩盖内存的慢速,完全放弃了对单线程速度的追求。
你觉得打印的a、b是什么呢?可以分出6种情况:
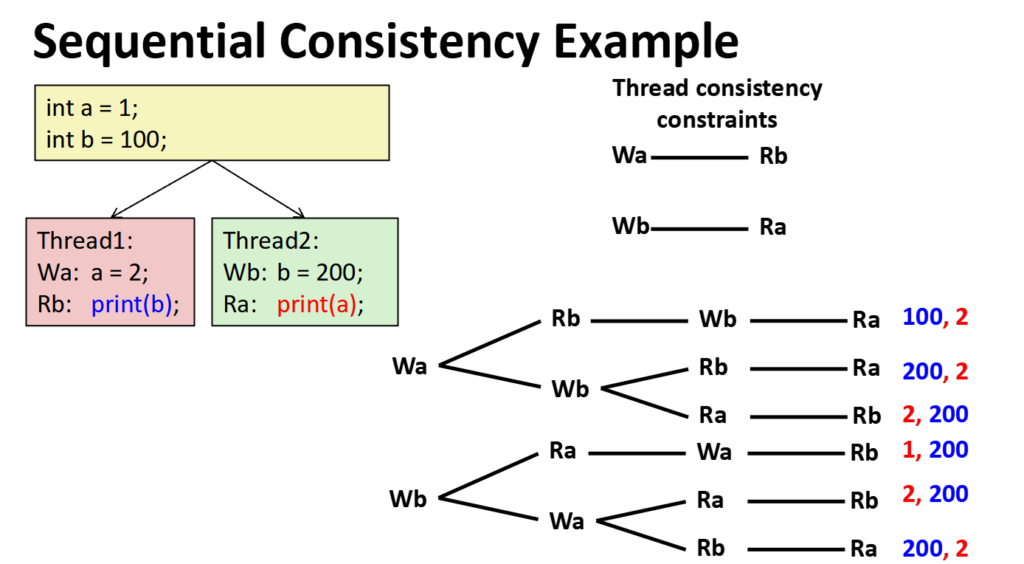
很明显,如果这个问题无法解决,那就会有大问题,让解决的方式是加个嗅探:
当线程1要修改a,通过缓存总线通知所有的线程,当线程2中发现自己有a时,会标记其为invalid,没有就不管,等要用到a时通过总线询问其他线程是否有a,如果有就将a传递给线程2,如果没有才回去内存中读取,避免了线程1还没往内存中写回线程2就想从内存中读取,但读取到脏数据的情况。
让我们通过下面的几张图理解该过程:
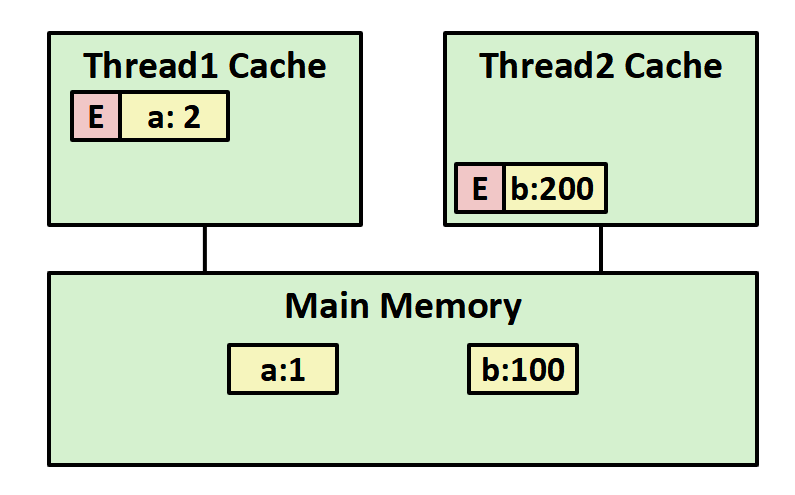
当线程1、2分别要修改a、b时,会标记其为E(Exclusive)(注意标记的单位是缓冲块,也就是64个字节),说明这些值为最新、独享的。
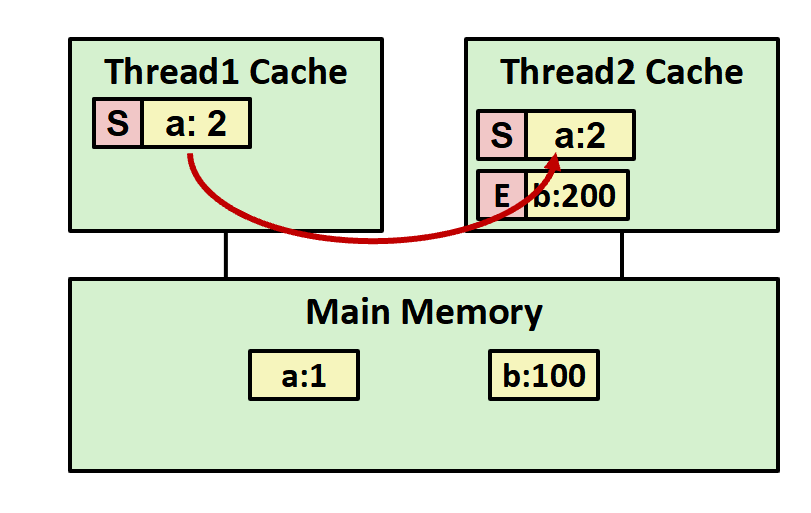
当线程2想读取a,这时候线程1告诉线程2它有,将a传递给线程2,此时E变成了S(Shared),代表最新,但不是独享的。
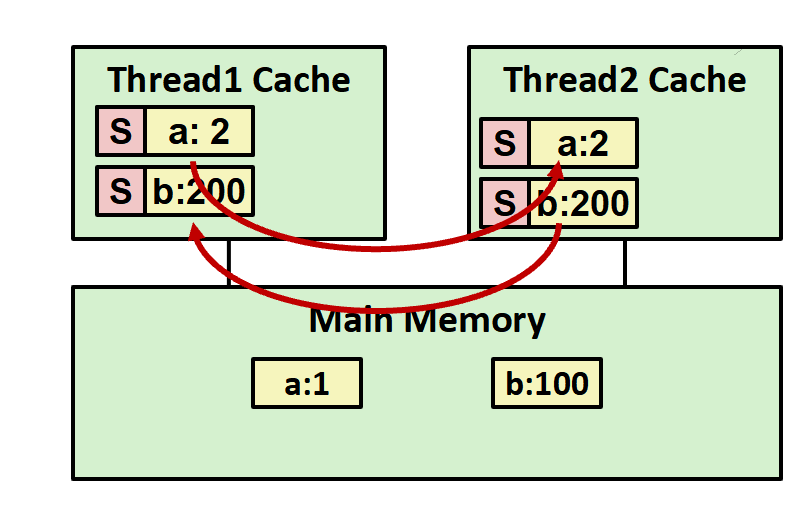
然后就完成了,成功打印了2、200。
接下我们看看怎么通过线程来求和1 + 2 + … + n,


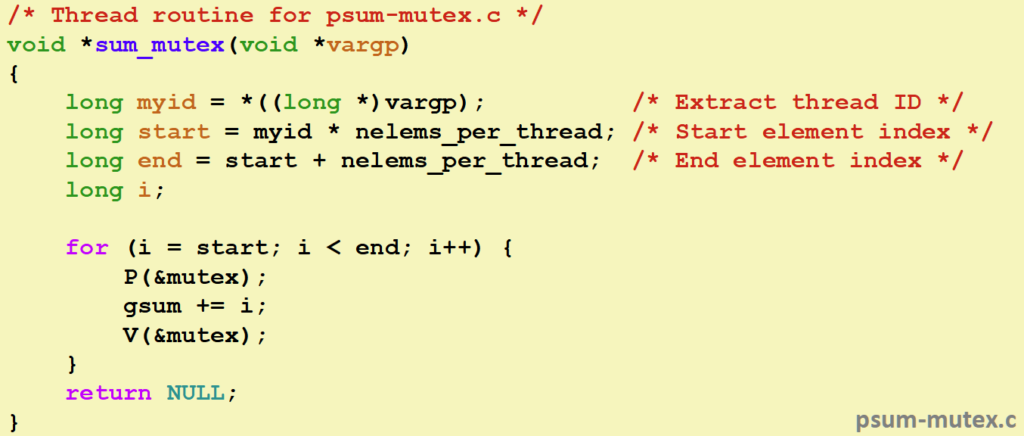
这就是代码的实现,看起来挺不错的对吧?你是否注意到了,他这里的因为锁,并不是并行的,而是像我们上面那样排队执行,那怎么并行呢?思路很简单,让每个线程不重叠的求和一小段,最后将和加起来即可:

让我们再优化,通过本地变量先计算好,再访存放入到数组里面:
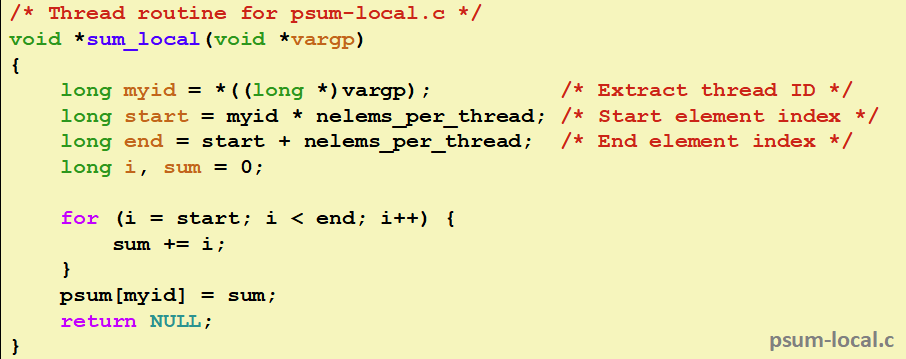
线程就这样加快了效率。
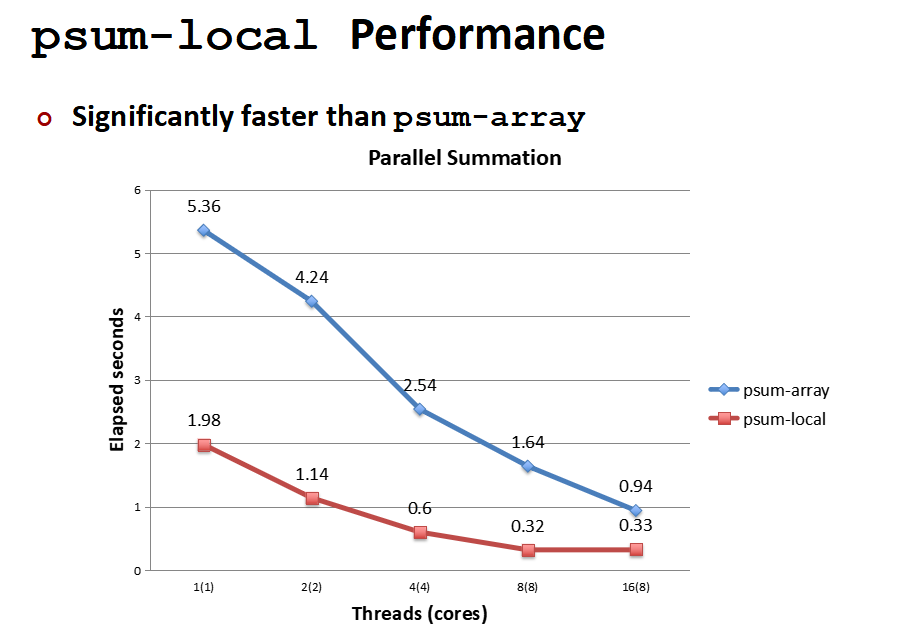
那是否还能继续提高呢?你是否注意到了缓存命中和数组的长度,一个缓存行的大小是64字节,从内存中读取会一次读64字节。
当array每个线程都分配了一个long空间,会有8个线程会内部互殴,也就是线程1在缓存总线喊这一块自己要修改,然后其他7个线程过来拿一份,然后另一个又修改又那一份,这样速度就慢了点,因此!让我们牺牲空间加快速度,让每个线程独享64字节的空间(这里的意识比如array[16],线程1在[0]处写,线程2在[8]处写,这样缓存拿取是并不会在其他线程中复制),这样速度又调高啦!









